tensorflow
在機器學習流行之前,都是基於規則的系統,因此做語音的需要瞭解語音學,做NLP的需要很多語言學知識,做深藍需要很多國際象棋大師。
而到後來統計方法成為主流之後,領域知識就不再那麼重要,但是我們還是需要一些領域知識或者經驗來提取合適的feature(特徵),feature的好壞往往決定了機器學習演算法的成敗。對於NLP來說,feature還相對比較好提取,因為語言本身就是高度的抽象;而對於Speech或者Image來說,我們人類自己也很難描述我們是怎麼提取feature的。比如我們識別一隻貓,我們隱隱約約覺得貓有兩個眼睛一個鼻子有個長尾巴,而且它們之間有一定的空間約束關係,比如兩隻眼睛到鼻子的距離可能差不多。但怎麼用圖元來定義”眼睛“呢?如果仔細想一下就會發現很難。當然我們有很多特徵提取的方法,比如提取邊緣輪廓等等。
但是人類學習似乎不需要這麼複雜,我們只要給幾張貓的照片給人看,他就能學習到什麼是貓。人似乎能自動“學習”出feature來,你給他看了幾張貓的照片,然後問貓有什麼特徵,他可能會隱隱預約地告訴你貓有什麼特徵,甚至是貓特有的特徵,這些特徵豹子或者老虎沒有。
深度學習為什麼最近這麼火,其中一個重要的原因就是不需要(太多)提取feature。
- 從機器學習的使用者來說,我們以前做的大部分事情是feature engineering,然後調一些參數,一般是為了防止過擬合。而有了深度學習之後,如果我們不需要實現一個CNN或者LSTM,那麼我們似乎什麼也不用幹。
- 但是深度學習也不是萬能的,至少現在的一個問題是它需要更強的計算能力才能訓練出一個比較好的模型。它還不能像人類那樣通過很少的訓練樣本就能學習很好的效果。
- 其實神經網路提出好幾十年了,為什麼最近才火呢?其中一個原因就是之前它的效果並不比非深度學習演算法好,比如SVM。
到了2006年之後,隨著計算能力的增強(尤其是GPU的出現)(Paper of Geroffy Hinton),深度神經網路在很多傳統的機器學習資料集上體現出優勢來之後,後來用到Image和Speech,因為它自動學出的feature不需要人工提取feature,效果提升更加明顯。這是否也說明,我們之前提取的圖像feature都不夠好,或者是根據人腦的經驗提取的feature不適合機器的模型?
- 很多人對深度學習頗有微詞的一個理由就是它沒有太多理論依據,更多的像蠻力的搜索——非常深的層數,幾千萬甚至上億參數,然後調整參數擬合輸入與輸出。其實目前所有的機器學習都是這樣,人類的大腦的學習有所不同嗎,不是神經元連接的調整嗎?
- 但不管怎麼說,從深度神經網路的使用者(我們這樣的工程師)的角度來說,如果我們選定了一種網路結構,比如CNN,那麼我們要做的就是根據經驗,選擇合適的層數,每層的神經元數量,啟動函數,損失函數,正則化的參數,然後使用validation資料來判定這次訓練的效果。從效果來說,一般層次越多效果越好(至少相對一兩層的網路來說),但是層次越多參數也越多,訓練就越慢。單機訓練一個網路花幾天甚至幾周的時間非常常見。因此用多個節點的電腦集群來訓練就是深度學習的核心競爭力——尤其對於使用者資料瞬息萬變的互聯網應用來說更是如此。
常見深度神經網路的訓練和問題
對於機器學習來說,訓練是最關鍵也最困難的部分,一般的機器學習模型都是參數化的模型,我們可以把它看成一個函數。
- 比如拿識別圖像來說,輸入x是這張圖片的每個位元值,比如MNIST的資料是2828的圖片,每個點是RGB的顏色值,那麼x就是一個2828*3的向量。而一個模型有很多參數,用w表示。輸出y是一個向量,比如MNIST的資料是0-9的10個數字,所以我們可以讓y輸出一個10維的向量,分別代表識別成0-9的置信度(概率),選擇最大的那個作為我們的識別結果(當然更常見的是最後一層是softmax而不是普通的啟動函數,這樣這個10維向量加起來等於1,可以認為是分類的機率)。
- 而訓練就是給這個模型很多(x,y),然後訓練的過程就是不斷的調整參數w,然後使得分類錯誤盡可能少(由於分類錯誤相對w不連續因而不可求導,所以一般使用一個連續的Loss Function)。
- 對於神經網路來說,標準的訓練演算法就是反向傳播演算法(BackPropagation)。從數學上來說就是使用(隨機)梯度下降演算法,求Loss Function對每個參數的梯度。另外我們也可以從另外一個角度來看反向傳播演算法,比如最後一層的神經網路參數,直接造成錯誤(Loss);而倒數第二層的神經網路參數,通過這一次的啟動函數影響最後一層,然後間接影響最終的輸出。反向傳播演算法也可以看成錯誤不斷往前傳播的過程。
由於深度神經網路的參數非常多,比如GoogleNet, 2014年ILSVRC挑戰賽冠軍,將Top5 的錯誤率降低到6.67%,它是一個22層的CNN,有5百多萬個參數。所以需要強大的計算資源來訓練這麼深的神經網路。
- CNN是Image領域常見的一種深度神經網路。由Yann LeCun提出,通過卷積來發現位置無關的feature,而且這些feature的參數是相同的,從而與全連接的神經網路相比大大減少了參數的數量。
- 最開始的改進是使用GPU來加速訓練,GPU可以看成一種SIMT的架構,和SIMD有些類似,但是執行相同指令的warp裡的32個core可以有不同的代碼路徑。對於反向傳播演算法來說,基本計算就是矩陣向量乘法,對一個向量應用啟動函數這樣的向量化指令,而不像在傳統的代碼裡會有很多if-else這樣的邏輯判斷,所以使用GPU加速非常有用。但即使這樣,單機的計算能力還是相對有限的。
從數學上來講,深度神經網路其實不複雜,我們定義不同的網路結構,比如層次之間怎麼連接,每層有多少神經元,每層的啟動函數是什麼。前向演算法非常簡單,根據網路的定義計算就好了。
- 而反向傳播演算法就比較複雜了,所以現在有很多深度學習的開源框架來幫助我們把深度學習用到實際的系統中。
tensorflow
- TensorFlow是一個採用資料流程圖(data flow graphs),用於數值計算的開源軟體庫。節點(Nodes)在圖中表示數學操作,圖中的線(edges)則表示在節點間相互聯繫的多維資料陣列,即張量(tensor)。TensorFlow 最初由Google brain小組的研究員和工程師們開發出來,用於機器學習和深度神經網路方面的研究,但這個系統的通用性使其也可廣泛用於其他計算領域。
什麼是資料流程圖(Data Flow Graph)
- 資料流程圖用nodes和edges的有向圖來描述數學計算。
- node 一般用來表示施加的數學操作,但也可以表示資料登錄(feed in)的起點/輸出(push out)的終點,或者是讀取/寫入持久變數(persistent variable)的終點。
- edge表示node之間的輸入/輸出關係。
- 這些資料edge可以輸運“size可動態調整”的多維資料陣列,即“張量”(tensor)。
- 張量從圖中流過的直觀圖像是這個工具取名為“Tensorflow”的原因。一旦輸入端的所有張量準備好,節點將被分配到各種計算設備完成非同步並行地執行運算。
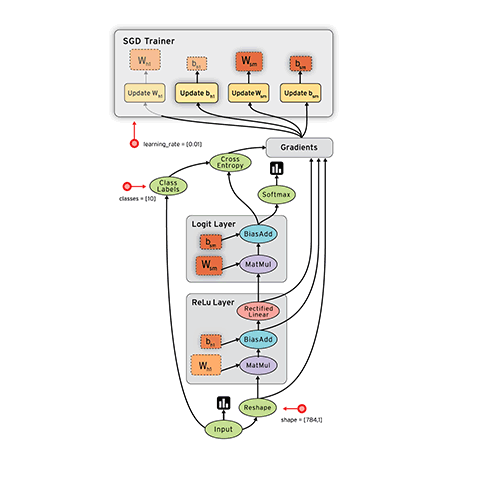
核心資料結構
class tf.Graph
-
- A TensorFlow computation, represented as a dataflow graph.
tensorflow預設有default graph,可使用tf.get_default_graph()取得,若未指定graph時,所有的操作都是在default graph中執行。
c = tf.constant(4.0)
assert c.graph is tf.get_default_graph() # True
tf.Graph.as_default()
- Returns a context manager that makes this Graph the default graph.
- 如果要使用自訂的graph,可用以下的方法指定:
g = tf.Graph()
with g.as_default():
# Define operations and tensors in `g`.
c = tf.constant(30.0)
assert c.graph is g
tf.Graph.device(device_name_or_function)
Returns a context manager that specifies the default device to use.
device_name_or_function可為device name的字串或是device function或是None:
- If it is a device name string, all operations constructed in this context will be assigned to the device with that name, unless overridden by a nested device() context.
- f it is a function, it will be treated as a function from Operation objects to device name strings, and invoked each time a new Operation is created. The Operation will be assigned to the device with the returned name.
- If it is None, all device() invocations from the enclosing context will be ignored.
valid syntax of device name strings, see the documentation in DeviceNameUtils.
with g.device('/gpu:0'):
# All operations constructed in this context will be placed
# on GPU 0.
with g.device(None):
# All operations constructed in this context will have no
# assigned device.
# Defines a function from `Operation` to device string.
def matmul_on_gpu(n):
if n.type == "MatMul":
return "/gpu:0"
else:
return "/cpu:0"
with g.device(matmul_on_gpu):
# All operations of type "MatMul" constructed in this context
# will be placed on GPU 0; all other operations will be placed
# on CPU 0.