MPICH程式設計
- C語言中使用MPI須include "mpi.h"
- MPI函式名稱均以MPI_開頭,且之後的第一個字母大寫,其餘小寫。
每個MPI函式都會回傳一個整數,其值為ERROR_CODE。
- 當函式執行成功時,會回傳error code MPI_SUCCESS
寫MPI程式時,我們常常須要知道以下兩個問題的答案:
- 任務應由多少個行程來進行平行計算?
- 我是那一個行程?
MPI程式測試
#include <stdio.h>
#include "mpi.h"
int main(int argc, char* argv[]){
MPI_Init(NULL, NULL);
printf("hello world\n");
MPI_Finalize();
return 0;
}
#include <stdio.h>
#include <mpi.h>
int main(int argc, char *argv[]){
int n = 0 , total = 0;
// 初始化MPI
MPI_Init(&argc, &argv);
// 此函數可得到目前正在執行的processs 編號, 且放在n當中
MPI_Comm_rank(MPI_COMM_WORLD, &n);
// 此函數可得到目前所有process的個數,存入total當中
MPI_Comm_size(MPI_COMM_WORLD, &total);
printf("This is Process %d of %d\n", n+1, total);
// 結束MPI
MPI_Finalize();
return 0;
}
編譯檔案: mpicc -o mpi_hello mpi_hello.c
- c使用mpicc, c++使用mpicxx編譯。
執行檔案: mpiexec -n 4 ./mpi_hello
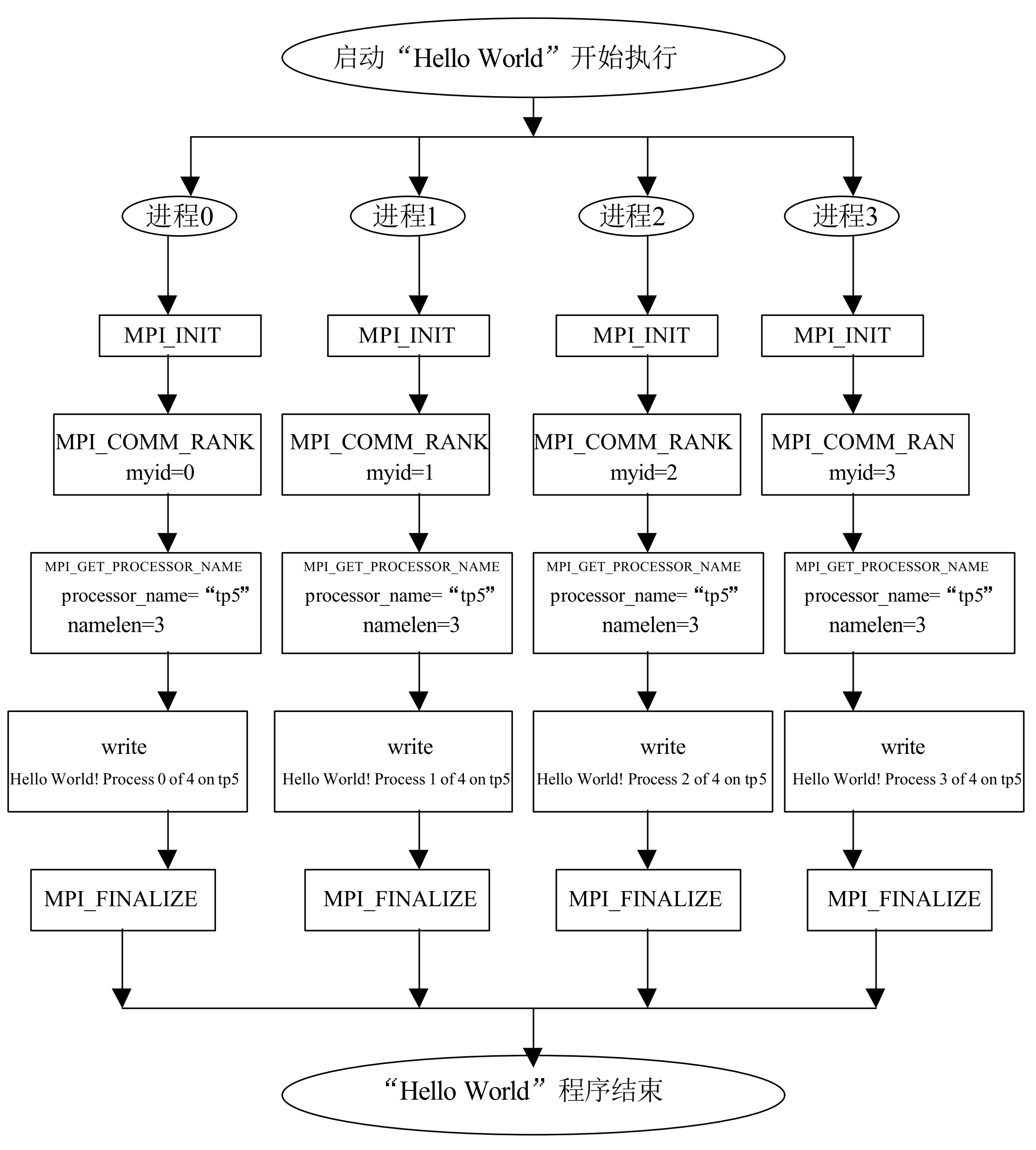
- 可得到MPI程式的框架結構為:
- 引入head file(mpi.h)
- 相關變數宣告
- 程式本體開始(MPI_Init)
- 程式內容,計算與通信
- 程式結束(MPI_Finalize)
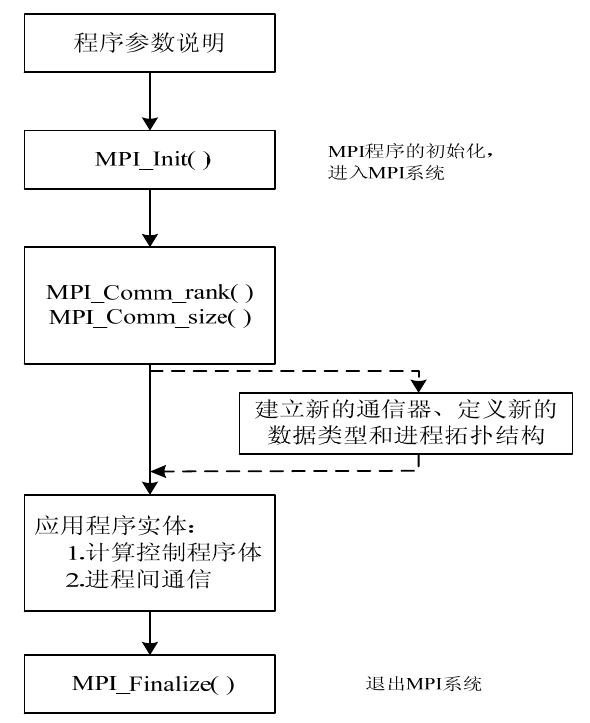
MPI函數
MPI2有287個函數,而MPI3中有400多個函數,相當的龐大,但是基本的函數主要為以下6個。
MPI函數中,參數主要有三類:IN、OUT、INOUT。
- IN:調用部份傳遞給MPI的參數,MPI只可使用,但不可修改此參數。
- OUT:MPI回傳給調用部份的結果參數,該參數的初始值對於MPI沒有任何意義。
- INOUT:調用部份首先將該參數傳遞給MPI,MPI對此參數引用、修改後,再將結果傳回給外部引用,因此該參數的初始值與回傳值均有意義。
- 注意:如果某一個參數在調用前後沒有改變(如pointer或是class的位置),但是其指向的記憶體內容改變了,則此變數仍應被說明為OUT或INOUT。
基本API
- 初始化
//這句應該放在所有平行作業的最前面。
int MPI_Init(int *argc, char*argv[]);
//是否初始化, 結果保存在flag中
int MPI_Initialized(int *flag);
- 平行處理結束
int MPI_Finalize();
- rank和進程數目
- comm為MPI_COMM_WORLD時,表示當前程式所有能用的進程。
- 一般,上面這兩句在大部分MPI程式中都是緊挨著MPI_init()的。
// 把comm通信下的processor的個數存入size中
int MPI_Comm_size(MPI_Comm comm, int *size);
// 當前進程的的標識存入rank中(0 ~ size-1)
int MPI_Comm_rank(MPI_Comm comm, int *rank);
//使用這兩個函數,可以方便的實現master-slave的並行模式。
if ( rank == 0 ) DoMaster();
else if ( rank == 1 ) DoSlave1();
else if ( rank == 2 ) DoSlave2();
- 時間測定
//程式此刻的時間戳記
int MPI_Wtime(void);
//兩個時鐘脈衝間隔
int MPI_Wtick(void);
P2P通信規範
點對點通信就是只涉及到兩個processor之間的消息傳輸。也就是send和recv。首先,先看一段點對點通信的例子:
- 這一段中使用MPI_Send()和MPI_Recv來實現master和slave之間的hello。使用的通信是較為簡單的阻塞式通信。
- 而通信方式分為阻塞通信(Blocking)和非阻塞通信(Non-blocking)。
- 關於阻塞和非阻塞,區別無非就是調用後需不需要掛起等待。
- 以下範例是rank=0的行程向其它rank=1,~size-1發訊息後,再等待其它行程發訊息回來的範例。
通訊子(communicator): MPI_COMM_WORLD是可使用行程的集合,所有參與平行計算的行程可以組合為一個或多個通信組。
- 一但執行MPI_Init後,MPI程式的所有行程形成一個預設的群組,即為MPI_COMM_WORLD。
- 此參數限定了參加通訊的行程範圍。
#include <stdio.h>
#include <string.h>
#include <mpi.h>
int main(int argv, char* argc[]){
int rank, tot, i;
char msg[128], rev[128];
MPI_Status state;
MPI_Init(&argv, &argc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &tot);
if (rank == 0){
for(i = 1; i < tot; i++){
sprintf(msg,"hello, %d, this is zero, I'am your master", i);
MPI_Send(msg, 128, MPI_CHAR, i, 0, MPI_COMM_WORLD);
}
for(i = 1; i < tot; i++){
MPI_Recv(rev, 128, MPI_CHAR, i, 0, MPI_COMM_WORLD, &state);
printf("P%d got: %s\n", rank, rev);
}
}else{
MPI_Recv(rev, 128, MPI_CHAR, 0, 0, MPI_COMM_WORLD, &state);
printf("P%d got: %s\n", rank, rev);
sprintf(msg, "hello, zero, this is %d, I'am your slave", rank);
MPI_Send(msg, 128, MPI_CHAR, 0, 0, MPI_COMM_WORLD);
}
MPI_Finalize();
return 0;
}
阻塞通信
- 在阻塞通信中,有四種模式:
- 標準通信模式(The Standard mode): 標準通信模式下,使不使用緩衝區。是由MPI本身決定的。緩衝區不是MPI的標準,但允許是MPI某個實現的一部分。 如果有緩衝區,每個processor都有獨立的一個的system buffer。如下圖所示:
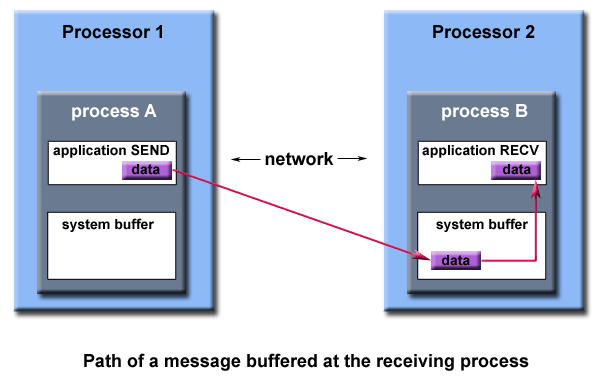
討論緩衝區時要區別system buffer和application buffer。
- system buffer的特點是:
- 對程式設計師透明,由MPI底層控制;
- 資源有限,很容易耗盡;
- 可以提高程式的性能,因為此時send/recv操作實際上是非同步的;
- application buffer的特點是:
- 供使用者使用的記憶體。比如你定義變數使用的記憶體。
- 對帶有system buffer的情況來說,阻塞發送實際上指的是成功將要發送的內容,拷貝到接收端的system buffer中的這一過程。阻塞接收實際上是指向system buffer發送請求到application buffer獲得資料的過程。
- system buffer的特點是:
相關API: ```c int MPI_Send(void buff, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm); int MPI_Recv(void buff, int count, MPI_Datatype type, int source, int tag, MPI_Comm comm, MPI_Status *status); MPI_Status status;
status.MPI_SOURCE //資訊來源 status.MPI_TAG //信息的Tag MPI_Get_count(MPI_Status status, MPI_datatype type, int count) //多少個該類型的資料
* 其中(buff, count, type)三元組在所有涉及通信的過程中都有,而且都是最開始的三個參數。表示資訊在記憶體(緩衝區)中的指標,發送的數目,以及資料的類型。
+ dest(ination)和source則表示資訊的目的地和來源, MPI中均以rank辦識之。
+ 而tag表示消息的一個標識。也有MPI_ANY_SOURCE和MPI_ANY_TAG這兩個值,表示接收所有source,所有tag的資訊。
+ comm這個參數為communicator,即群組內的可用行程。
+ status這個參數存儲這接收到的資訊的狀態。
* 對於資料類型,基本的類型與對應如下。
| MPI_Type | C |
| --- | --- |
|MPI_BYTE | NA |
|MPI_CHAR | signed char|
|MPI_DOUBLE | double|
|MPI_FLOAT | float|
|MPI_INT | int |
|MPI_LONG| long|
|MPI_LONG_DOUBLE | long double|
|MPI_PACKED | NA|
|MPI_SHORT | short |
|MPI_UNSIGNED_CHAR | unsigned char|
|MPI_UNSIGNED | unsigned int|
|MPI_UNSIGNED_LONG | unsigned long|
|MPI_UNSIGNED_SHORT | unsigned short|
* 類型匹配規則:
+ 有類型資料的通訊,發送方與接受方均使用相同的資料類型。
+ 無類型資料的通訊,發送方與接受方均使用MPI_BYTE處理。
+ 打包八的通訊,發送方與接受方均使用MPI_PACKED處理。
* MPI傳送資料時,下列資訊應匹配:
+ 資料類型
+ send與recv,避免deadlock
+ tag相符
### Message envelope
* Message envelope: MPI辦識一個訊息的資訊包含四個域
+ source:由send的process rank隱含唯一確定。
+ destination: send函式確定
+ tag: 由send函式確定
+ communicator: 預設為MPI_COMM_WORLD,也可自訂group。
### 使用tag的原因
* 原因1:傳送資料順序不同
<figure>
<img src="/mpi/figure/mpi_tag.png" height="300"/>
<figcaption> 使用tag可避免傳送資料順序不同的誤判.</figcaption>
</figure>
* 上圖表示行程P將傳送A的前32 bytes到X中,且傳送B的前16 bytes到Y中。
+ 如果B後發送,但是先傳送到行程Q中時,若無指定tag時,會先被recv()接受存到X中得到錯誤的結果。
+ 如果明確使用tag時,則不會出現此種錯誤。
* 原因2: 簡化判斷來自不同行程的資訊
* 假設有兩個client processes P and R,各自發出request到server process Q。
```c
/*** 沒有使用tag時 ***/
// Process P
send(request1, 32, Q)
// Process R
send (request2, 32, Q)
// Process Q
while(true) {
recv(received_request, 32, Any_Process);
// 不容易判斷request從何而來
process_received_request;
}
/*** 使用tag時 ***/
// Process P
send(request1, 32, Q, tag1)
// Process R
send (request2, 32, Q, tag2)
// Process Q
while(true) {
recv(received_request, 32, Any_Process);
if (Status.Tag==tag1) process_received_request in one way;
if (Status.Tag==tag2) process_received_request in another way;
}
訊息匹配
接收buffer必須至少可以容納count個由datatype參數指明類型的資料。
- 接收buffer必須至少可以容納count個由datatype參數指明類型的資料
- 如果接收buf太小, 將導致溢出、出錯
訊息匹配
- 參數匹配dest,tag,comm/ source,tag,comm
- Source == MPI_ANY_SOURCE:接收任意行程來的資料
- Tag == MPI_ANY_TAG: 匹配任意tag值的訊息
在阻塞式計算中訊息傳遞不允許Source==Dest,否則會造成deadlock.
- 訊息傳遞被限制在同一個communicator中。
- 在send函式中必須指定唯一的接受者。
Status參數
Q: 當使用MPI_ANY_SOURCE或/和MPI_ANY_TAG接收消息時 當使用MPI_ANY_SOURCE或/和MPI_ANY_TAG接收消息時 如何確定消息的來源source 和tag值?
- Ans: 使用Status.MPI_SOURCE與Status.MPI_TAG。
Status還可用於返回實際接收到消息的長度
int MPI_Get_count(MPI_Status status, //In, status, 接收操作的返回值
MPI_Datatype datatype, //In, datatype, 接收緩衝區中元素的資料類型
int* count) //Out, 接受緩衝區中元素個數
- 下列的程式,如果有3個行程,則行程1、2誰會先向行程0發送訊息?
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "mpi.h"
int main(int argc, char* argv[]){
int numprocess;
int myid;
MPI_Status status;
char message[100];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &numprocess);
if(myid != 0){
sprintf(message, "hello!");
MPI_Send(message, strlen(message) + 1, MPI_CHAR, 0, 99, MPI_COMM_WORLD);
} else {
// myid == 0
for(int source = 1; source < numprocess; ++source){
MPI_Recv(message, 100, MPI_CHAR, source, 99, MPI_COMM_WORLD, &status);
printf("%s\n", message);
}
}
MPI_Finalize();
return EXIT_SUCCESS;
}
- 同步通信模式(The Synchronous mode) 理解上述的標準模式,同步模式就好說了。
- 所謂同步,指的是資訊傳輸終止于接收方已經開始將資料拷貝到Application Buffer中去。只有一個API:
MPI_Ssend(void *buff, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm);
- 準備好通信模式(The Ready mode) 僅僅在程式設計師100%確定發送時接收方已經準備好時使用。不過在MPI的各種實現中基本上和標準的MPI_Send一樣。
MPI_Rsend(void *buff, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm);
- 緩存通信模式(The Buffered mode) 人工開闢一片System Buffer給程式師使用,使用方式就如同標準通信模式帶緩存的情況。一般用來彌補System Buffer不足的缺點。
MPI_Bsend(void *buff, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comma);
MPI_Buffer_attach(void *buff, int size);
MPI_Buffer_detach(void *buff, int size);
- 以上這四中模式中,準備好模式是最快的,然而很少使用。應為這種情況最少。標準模式和緩存模式也足夠快,但增加了記憶體開銷。一般來說用來應付較小的通信。同步模式最慢,但也最可靠。一般用來應付資料量大的通信。
非阻塞通信
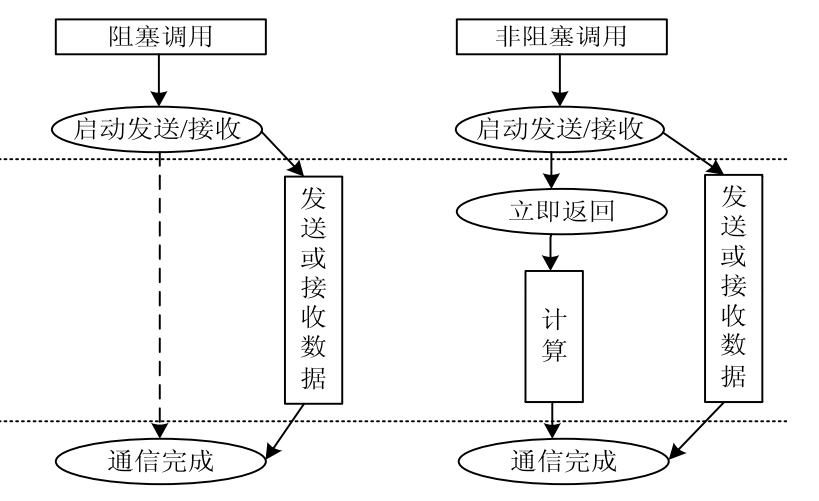
- 非阻塞通信一般用來重疊通信和計算。為了最大限度壓榨硬體而使用。
- 雖然非阻塞通信有諸如MPI_Issend,MPI_Ibsend,MPI_Irsend不過基本和前面大同小異。所謂非阻塞模式指的是在發送和接收的函式呼叫後立即返回,不管到底有沒有發送和接收到,而操作的正確性由Wait和Test類函數來保證。
- 也就是說,在一個非阻塞操作執行之後,在使用得到的資料之前要先wait或Test一下來保證這個資料是已經可用的。
int MPI_Isend(void *buf, int count, MPI_Datatype datatype, int dest,
int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Irecv(void *buf, int count, MPI_Datatype datatype,int source,
int tag, MPI_Comm comm, MPI_Request *request)
/* IN buf:發起緩衝區的起始位址
* IN count: 發起緩衝區的元素個數
* IN datatype: 發起緩衝區的資料型態
* IN dest: 目的行程rank
* IN tag: 訊息tag
* IN comm: communicator
* OUT request: 非阻塞通訊完成物件(handler)
*/
MPI_Wait(MPI_Request *request, MPI_Status *status);
MPI_Waitall(int count, MPI_Request *array_of_requests[], MPI_Status *array_of_statuses[]);
MPI_Test(MPI_Request *request, int *flag, MPI_status *status);
MPI_Testall(int count, MPI_Request *array_of_requests[], int *flag, MPI_Status *array_of_statuses[]);
- 這裡程式在執行MPI_Irev之後立即就返回了,程式繼續執行,然而此時訪問存儲的資料發現並沒有接收到。要到wait之後才確定。
#include <stdio.h>
#include <unistd.h>
#include "mpi.h"
int main(int argc, char *argv[]) {
int numtasks, rank, next, prev, buf[2], tag1=1, tag2=2;
MPI_Request reqs[4];
MPI_Status stats[4];
buf[0] = -1;
buf[1] = -1;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
prev = rank-1;
next = rank+1;
if (rank == 0) prev = numtasks - 1;
if (rank == (numtasks - 1)) next = 0;
MPI_Irecv(&buf[0], 1, MPI_INT, prev, tag1, MPI_COMM_WORLD, &reqs[0]);
MPI_Irecv(&buf[1], 1, MPI_INT, next, tag2, MPI_COMM_WORLD, &reqs[1]);
printf("buffer before wait%d %d\n",buf[0],buf[1]);
sleep(2);
MPI_Isend(&rank, 1, MPI_INT, prev, tag2, MPI_COMM_WORLD, &reqs[2]);
MPI_Isend(&rank, 1, MPI_INT, next, tag1, MPI_COMM_WORLD, &reqs[3]);
MPI_Waitall(4, reqs, stats);
printf("task %d got %d from prev\n",rank, buf[0]);
printf("task %d got %d from next\n",rank, buf[1]);
MPI_Finalize();
return 0;
}
// 結果
buffer before wait-1 -1
buffer before wait-1 -1
buffer before wait-1 -1
buffer before wait-1 -1
task 0 got 3 from prev
task 0 got 1 from next
task 1 got 0 from prev
task 1 got 2 from next
task 2 got 1 from prev
task 2 got 3 from next
task 3 got 2 from prev
task 3 got 0 from next
block vs non-block communication
Blocking:
- A blocking send routine will only "return" after it is safe to modify the application buffer (your send data) for reuse. Safe means that modifications will not affect the data intended for the receive task. Safe does not imply that the data was actually received - it may very well be sitting in a system buffer.
- A blocking send can be synchronous which means there is handshaking occurring with the receive task to confirm a safe send.
- A blocking send can be asynchronous if a system buffer is used to hold the data for eventual delivery to the receive.
- A blocking receive only "returns" after the data has arrived and is ready for use by the program.
Non-blocking:
- Non-blocking send and receive routines behave similarly - they will return almost immediately. They do not wait for any communication events to complete, such as message copying from user memory to system buffer space or the actual arrival of message.
- Non-blocking operations simply "request" the MPI library to perform the operation when it is able. The user can not predict when that will happen.
- It is unsafe to modify the application buffer (your variable space) until you know for a fact the requested non-blocking operation was actually performed by the library. There are "wait" routines used to do this.
- Non-blocking communications are primarily used to overlap computation with communication and exploit possible performance gains.
順序規則(Order Rules)
+ 發送方連著發送兩個消息給同一個接收方。先發的必被先收。
+ 接收放連著請求兩次同一個消息。先請求必先滿足。
+ 兩個發送方給一個接收方發同樣的消息,同時接收方只收一個,只有一個會被滿足。(Starvation)
+ 以上前提沒有使用多執行緒。
集合通信規範
- 集合通信指的是包含在同一個communicator下的全部processor的通信。分3個類型:
- Synchronization:強制所有processor都到達同步點。
- Data Movement:資料交換,有broadcast,scaater,gather等。
- Reductions:規約,將所有processor中的資料進行統計值計算。
#include "mpi.h"
#include <stdio.h>
#define SIZE 4
int main(int argc, char *argv[]) {
int numtasks, rank, sendcount, recvcount, source;
float sendbuf[SIZE][SIZE] = {
{1.0, 2.0, 3.0, 4.0},
{5.0, 6.0, 7.0, 8.0},
{9.0, 10.0, 11.0, 12.0},
{13.0, 14.0, 15.0, 16.0} };
float recvbuf[SIZE];
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
if (numtasks == SIZE) {
source = 1;
sendcount = SIZE;
recvcount = SIZE;
MPI_Scatter(sendbuf,sendcount,MPI_FLOAT,recvbuf,recvcount,
MPI_FLOAT,source,MPI_COMM_WORLD);
printf("rank= %d Results: %f %f %f %f\n",rank,recvbuf[0],
recvbuf[1],recvbuf[2],recvbuf[3]);
}
else
printf("Must specify %d processors. Terminating.\n",SIZE);
MPI_Finalize();
return 0;
}
集體同步
- 強制所有processor都運行到函式呼叫時才繼續執行之後的語句。
MPI_Barrier (MPI_Comm comm);
資料傳輸
- brodcast,scatter,gather,reduction的區別見下:
- 還有MPI_Allgather相當於每個processor都做一次gather。

int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype,int root, MPI_Comm comm);
int MPI_Scatter(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm);
int MPI_Gather(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm);
int MPI_Alltoall (void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcnt, MPI_Datatype recvtype, MPI_Comm comm);
規約(reduction)
- 類似map-reduce的reduce或是python中的reduce
int MPI_Reduce(void *sendbuf, void *recvbuf, int count, MPI_Datatype datatype,op, int root, MPI_Comm comm);
int MPI_Op_create(MPI_User_function *function, int commute, MPI_Op *op);
群組和通信器
- 即Groups和Communicators。
- 一个Group对应一个Communicators,Group的目的是使你可以给task分组。然后可以在组内进行更加Safe的通信。通过MPI_Group_incl来创建新组,MPI_Comm_create来创建新的通信器。
#include "mpi.h"
#include <stdio.h>
#define NPROCS 8
int main(int argc, char *argv[]) {
int rank, new_rank, sendbuf, recvbuf, numtasks, ranks1[4]={0,1,2,3}, ranks2[4]={4,5,6,7};
MPI_Group orig_group, new_group;
MPI_Comm new_comm;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
if (numtasks != NPROCS) {
printf("Must specify MP_PROCS= %d. Terminating.\n",NPROCS);
MPI_Finalize();
return 0;
}
sendbuf = rank;
/* Extract the original group handle */
MPI_Comm_group(MPI_COMM_WORLD, &orig_group);
/* Divide tasks into two distinct groups based upon rank */
if (rank < NPROCS/2) {
MPI_Group_incl(orig_group, NPROCS/2, ranks1, &new_group);
}
else {
MPI_Group_incl(orig_group, NPROCS/2, ranks2, &new_group);
}
/* Create new new communicator and then perform collective communications */
MPI_Comm_create(MPI_COMM_WORLD, new_group, &new_comm);
MPI_Allreduce(&sendbuf, &recvbuf, 1, MPI_INT, MPI_SUM, new_comm);
MPI_Group_rank (new_group, &new_rank);
printf("rank= %d newrank= %d recvbuf= %d\n",rank,new_rank,recvbuf);
MPI_Finalize();
return 0;
}