集合通訊(Collective communication)
- 通信空間中的所有進程都參與通信操作,通信空間中的所有進程都參與通信操作。
- 每一個進程都需要調用該操作函數,每一個進程都需要調用該操作函式。
- 分為一對多、多對一、同步。
| 類別 | 函式 | 功能 |
|---|---|---|
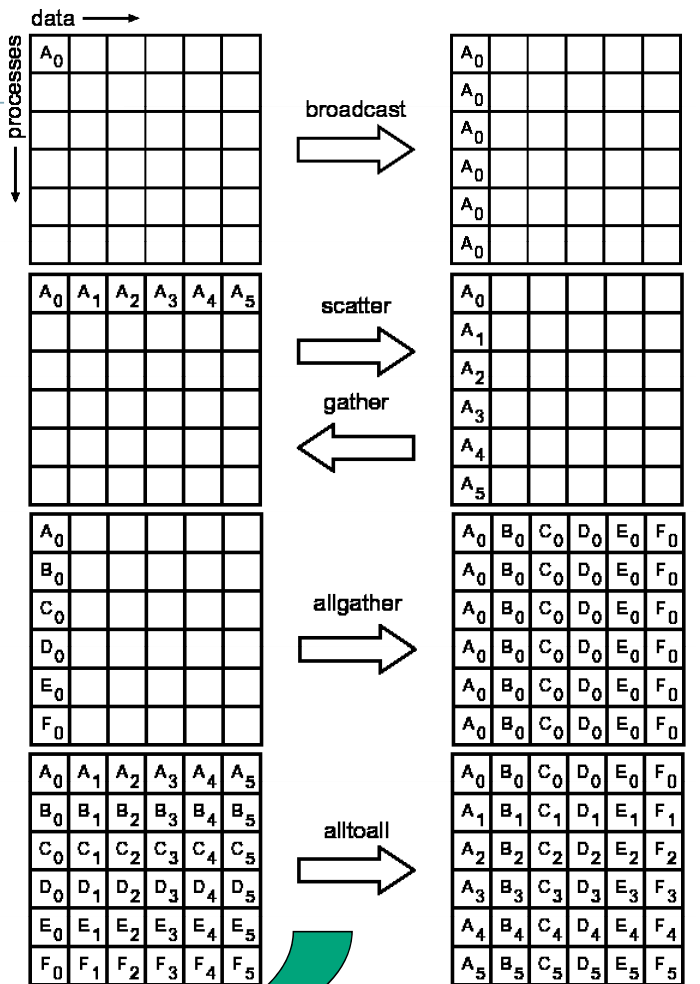
| 資料移動 | MPI_Bcast | 一對多,資料廣播 |
| 資料移動 | MPI_Gather | 多對一,資料匯合 |
| 資料移動 | MPI_Gatherv | MPI_Gather的一般形式 |
| 資料移動 | MPI_Allgather | MPI_Gather的一般形式 |
| 資料移動 | MPI_Allgatherv | MPI_Allgather的一般形式 |
| 資料移動 | MPI_Scatter | 一對多,資料分散 |
| 資料移動 | MPI_Scatterv | MPI_Scatter的一般形式 |
| 資料移動 | MPI_Alltoall | 多對多,置換資料(全交換) |
| 資料移動 | MPI_Alltoallv | MPI_Alltoall的一般形式 |
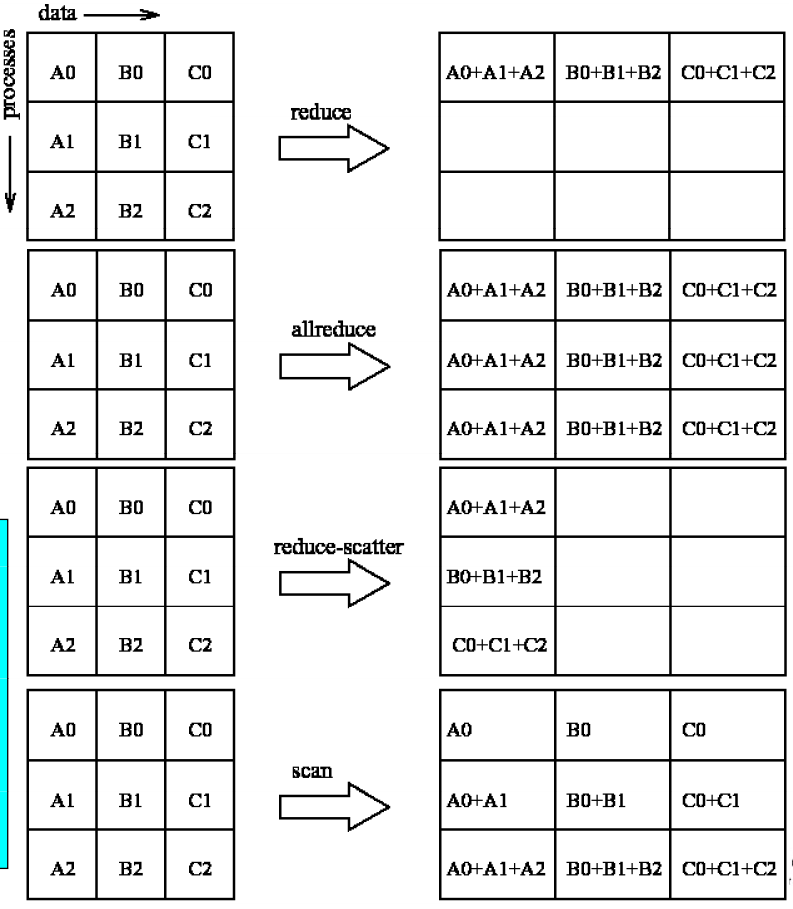
| 資料聚集 | MPI_Reduce | 多對一,資料歸約 |
| 資料聚集 | MPI_AllReduce | MPI_Reduce的一般形式,結果會存在於所有行程 |
| 資料聚集 | MPI_Reduce_scatter | 將結果scatter到每個行程 |
| 資料聚集 | MPI_Scan | 前綴操作 |
| 同步 | MPI_Barrier | 同步操作 |
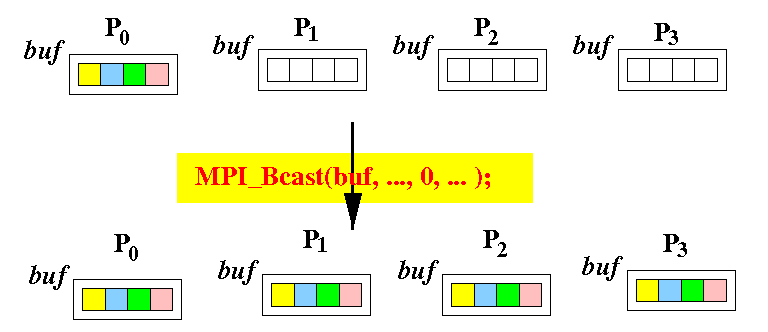
Brocadcast
- MPI根據rootID將buffer中的資料傳送給通訊群組comm中的所有行程。
MPI_Bcast(void* buffer,
int count,
MPI_Datatype datatype,
int rootID,
MPI_Comm comm )
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "mpi.h"
int main(int argc, char **argv){
char buff[128];
int secret_num;
int numprocs;
int myid;
int i;
MPI_Status stat;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
if ( myid == 0 ){
secret_num = atoi(argv[1]);
}
MPI_Bcast (&secret_num, 1, MPI_INT, 0, MPI_COMM_WORLD);
if ( myid == 0 ) {
for( i = 1; i < numprocs; i++) {
MPI_Recv(buff, 128, MPI_CHAR, i, 0, MPI_COMM_WORLD, &stat);
printf("buff: %s\n", buff);
}
} else {
sprintf(buff, "Processor %d knows the secret code: %d",
myid, secret_num);
MPI_Send(buff, 128, MPI_CHAR, 0, 0, MPI_COMM_WORLD);
}
MPI_Finalize();
return 0;
}
// mpiexec -n 5 ./bcast 10
buff: Processor 1 knows the secret code: 10
buff: Processor 2 knows the secret code: 10
buff: Processor 3 knows the secret code: 10
buff: Processor 4 knows the secret code: 10
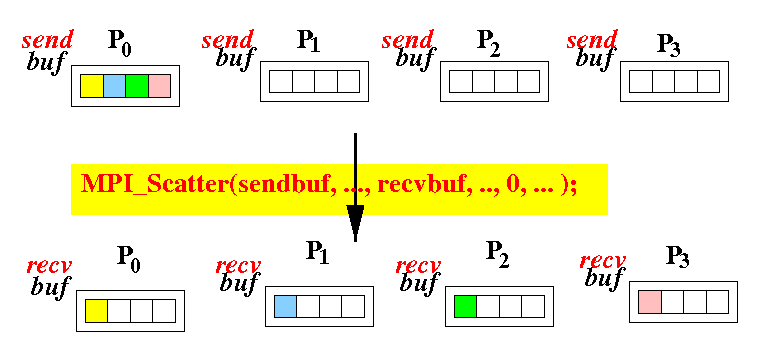
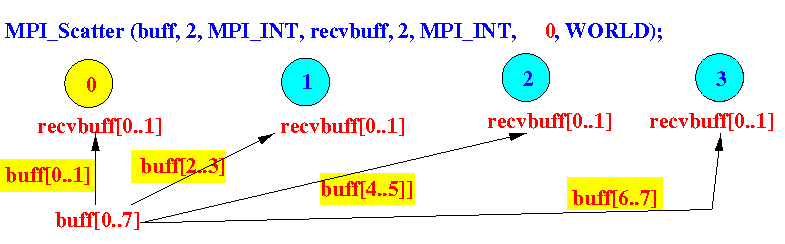
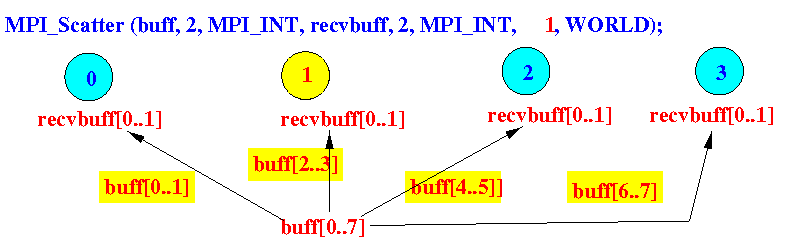
Scatter
scatter將array中的資料切成多份分給不同行程。
- sendbuf中放置資料
- sendcount為資料切成的份量數
注意:
- sendtype與recvtype應相同
- sendcount與recvcount應相同
- 發送的node也會有一份切好的資料在recvbuf中。
- 接收的node永遠在recvbuf中接收資料。
MPI_Scatter(void* sendbuf, // Distribute sendbuf evenly to recvbuf
int sendcount, // # items sent to EACH processor
MPI_Datatype sendtype,
void* recvbuf,
int recvcount,
MPI_Datatype recvtype,
int rootID, // Sending processor !
MPI_Comm comm)
#include <stdio.h>
#include <stdlib.h>
#include "mpi.h"
int main(int argc, char* argv[]){
int buff[100];
int recvbuff[2];
int numprocs;
int myid;
int i, k;
int mysum;
MPI_Status stat;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
if ( myid == 0 ) {
printf("We have %d processors\n", numprocs);
// -----------------------------------------------
// Node 0 prepare 2 number for each processor
// [1][2] [3][4] [5][6] .... etc
// -----------------------------------------------
k = 1;
for ( i = 0; i < 2*numprocs; i += 2 ){
buff[i] = k++;
buff[i+1] = k++;
}
}
// ------------------------------------------
// Node 0 scatter the array to the processors:
// ------------------------------------------
MPI_Scatter (buff, 2, MPI_INT, recvbuff, 2, MPI_INT, 0, MPI_COMM_WORLD);
if ( myid == 0 ) {
mysum = recvbuff[0] + recvbuff[1];
printf("Processor %d, sum = %d\n", myid, mysum);
for( i = 1; i < numprocs; i++) {
MPI_Recv(&mysum, 1, MPI_INT, i, 0, MPI_COMM_WORLD, &stat);
printf("Processor %d, sum = %d\n", myid, mysum);
}
} else {
mysum = recvbuff[0] + recvbuff[1];
MPI_Send(&mysum, 1, MPI_INT, 0, 0, MPI_COMM_WORLD);
}
MPI_Finalize();
return EXIT_SUCCESS;
}
// mpiexec -n 4 ./scatter
We have 4 processors
Processor 0, sum = 3
Processor 0, sum = 7
Processor 0, sum = 11
Processor 0, sum = 15
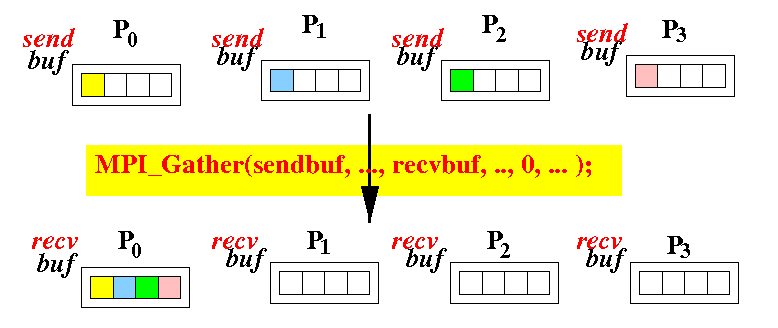
Gatter
通常與scatter一起使用。
- sendbuf: the data (must be valid for ALL processors)
- sendcount: number of items that will be sent to the rootID process
the number of items received in recvbuf of the rootID process will be equal to recvcount * numprocs
注意:
- sendtype與recvtype應相同
- sendcount與recvcount應相同
MPI_Gather(void* sendbuf,
int sendcount,
MPI_Datatype sendtype,
void* recvbuf,
int recvcount,
MPI_Datatype recvtype,
int rootID,
MPI_Comm comm)


#include <stdio.h>
#include <stdlib.h>
#include "mpi.h"
int main(int argc, char* argv[]){
int buff[100] ={};
int recvbuff[2] = {};
int numprocs;
int myid;
int i, k;
int mysum;
MPI_Status stat;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
if ( myid == 0 ) {
printf("We have %d processors\n", numprocs);
// -----------------------------------------------
// Node 0 prepare 2 number for each processor
// [1][2] [3][4] [5][6] .... etc
// -----------------------------------------------
k = 1;
for ( i = 0; i < 2*numprocs; i += 2 ){
buff[i] = k++;
buff[i+1] = k++;
}
}
// ------------------------------------------
// Node 0 scatter the array to the processors:
// ------------------------------------------
MPI_Scatter (buff, 2, MPI_INT, recvbuff, 2, MPI_INT, 0, MPI_COMM_WORLD);
mysum = recvbuff[0] + recvbuff[1]; // Everyone calculate sum
// ------------------------------------------
// Node 0 collects the results in "buff":
// ------------------------------------------
MPI_Gather (&mysum, 1, MPI_INT, &buff, 1, MPI_INT, 0, MPI_COMM_WORLD);
if ( myid == 0 ) {
for( i= 0; i < numprocs; i++) {
printf("Processor %d, sum = %d\n", i, buff[i]);
}
}
MPI_Finalize();
return EXIT_SUCCESS;
}
// mpiexec -n 4 ./gather
We have 4 processors
Processor 0, sum = 3
Processor 1, sum = 7
Processor 2, sum = 11
Processor 3, sum = 15
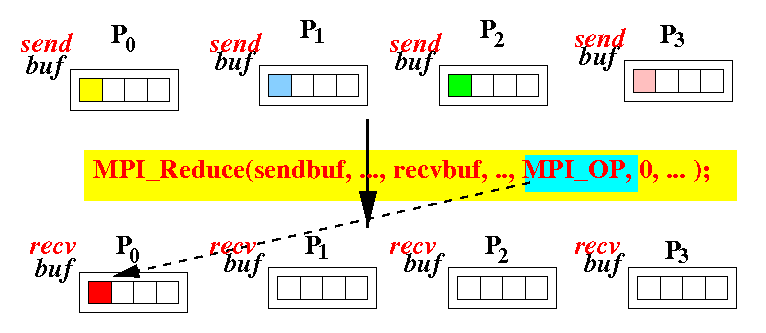
Reduce
- gather在把資料收集合回來後,仍然需要再計算才能得到最後的結果。
使用reduce可以一邊gather同時計算。
- sendbuf: the data (must be valid for ALL processors)
- recvbuf: buffer used to receiving data and simultaneously perform the "reducing operation".
- recvcount: number of items to receive (per processor)
注意:
- sendtype與recvtype應相同
- sendcount與recvcount應相同
MPI_Reduce(void* sendbuf,
void* recvbuf,
int recvcount,
MPI_Datatype recvtype,
MPI_Op op, // MPI支援的operator
int rootID,
MPI_Comm comm)

- MPI支援的reduction operator如下。
| Opeartion | 說明 |
|---|---|
| MPI_MAX | 找最大值 |
| MPI_MIN | 找最小值 |
| MPI_PROD | 所有元素相乘 |
| MPI_LAND | 所有元素做logical and |
| MPI_BAND | 所有元素做bitwise and |
| MPI_LOR | 所有元素做logical or |
| MPI_BOR | 所有元素做bitwise or |
| MPI_LXOR | 所有元素做logical xor |
| MPI_BXOR | 所有元素做bitwise xor |
| MPI_MAXLOC | 找最大值與擁有此值的process rank |
| MPI_MINLOC | 找最小值與擁有此值的process rank |
// pi.c
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include "mpi.h"
double func(double a){
return (2.0/sqrt(1 - a*a));
}
int main(int argc, char* argv[]){
int N = 0;
double w, x;
int i, myid;
double mypi, final_pi;
int num_procs = 0;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
if(myid == 0)
N = atoi(argv[1]);
MPI_Bcast(&N, 1, MPI_INT, 0, MPI_COMM_WORLD);
w = 1.0/(double)N;
mypi = 0.0;
for(i=myid; i<N; i+=num_procs){
x = w * (i + 0.5);
mypi += w*func(x);
}
MPI_Reduce(&mypi, &final_pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if(myid == 0)
printf("Pi = %f\n", final_pi);
MPI_Finalize();
return EXIT_SUCCESS;
}
//mpiexec -n 10 ./pi 1000000
Pi = 3.140737s
自訂reduce function
MPI_Op_create的參數
- function: the function that you want to use to perform the reduction operation
- commute (交換性): set this parameter to 0 (zero) if the operation does NOT commute, otherwise (if "a op b" = "b op a"), set it to 1 (ONE)
- op: return value: the operation handle that you need to pass to MPI_Reduce().
自訂函數的參數
- in: pointer to the first operand
- inout: pointer to the second operand
- len: number of elements in in and inout
- datatype: the type of data stored in in and inout
MPI_Op_create(MPI_User_function *function,
int commute,
MPI_Op *op)
void function_name( void *in,
void *inout,
int *len,
MPI_Datatype *datatype);
// pi2.c
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include "mpi.h"
void myAdd( void *a, void *b, int *len, MPI_Datatype *datatype){
int i;
if ( *datatype == MPI_INT )
{
int *x = (int *)a; // Turn the (void *) into an (int *)
int *y = (int *)b; // Turn the (void *) into an (int *)
for (i = 0; i < *len; i++)
{
*y = *x + *y;
x++;
y++;
}
}
else if ( *datatype == MPI_DOUBLE )
{
double *x = (double *)a; // Turn the (void *) into an (double *)
double *y = (double *)b; // Turn the (void *) into an (double *)
for (i = 0; i < *len; i++)
{
*y = *x + *y;
x++;
y++;
}
}
}
double func(double a){
return (2.0/sqrt(1 - a*a));
}
int main(int argc, char* argv[]){
int N = 0;
double w, x;
int i, myid;
double mypi, final_pi;
int num_procs = 0;
MPI_Op myOp;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
if(myid == 0)
N = atoi(argv[1]);
MPI_Bcast(&N, 1, MPI_INT, 0, MPI_COMM_WORLD);
w = 1.0/(double)N;
mypi = 0.0;
for(i=myid; i<N; i+=num_procs){
x = w * (i + 0.5);
mypi += w*func(x);
}
MPI_Op_create( myAdd, 1, &myOp);
MPI_Reduce(&mypi, &final_pi, 1, MPI_DOUBLE, myOp, 0, MPI_COMM_WORLD);
if(myid == 0)
printf("Pi = %f\n", final_pi);
MPI_Finalize();
return EXIT_SUCCESS;
}
Barrier
- 在設置Barrier的地方,所有的行程都會停在這一點直到所有的行程均已執行到此處。
MPI_Barrier( MPI_Comm comm )