MapReduce介紹
- MapReduce模型是一種主要用來處理大量資料的程式模型,並使用於電腦叢集的分散式運算,程式設計者只需學習使用單純的API(包含map函數和reduce函數),就可輕易的將job分割成許多tasks平行執行在許多node上。
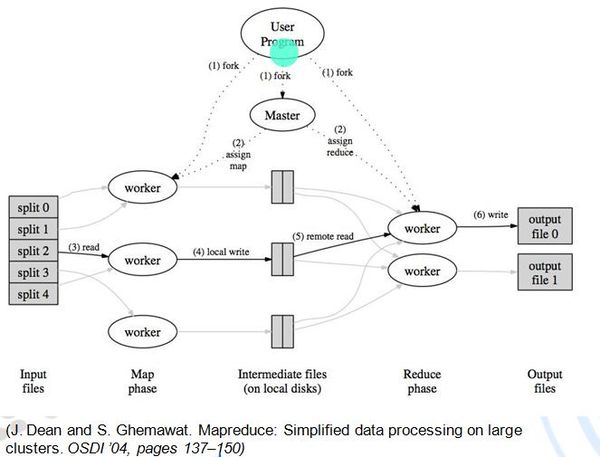
- MapReduce流程:
- fork: 由User寫好的Program開始,將要執行的MapReduce程式複製到master與每一台worker node上.
- assign map: 由Master node決定Map和Reduce兩個function內的程式,分別要用哪些Worker node執行.
- read: split指的是原輸入資料分割後的資料區塊(在Hadoop中input files要存放在HDFS分散式檔案系統上),要執行map程式的Worker node,就會照著master分配的資料link,到HDFS上去找到他要執行的資料區塊。
- local write: 將資料區塊依照Map程式處理完後,會產生中間資料(intermediate files),暫存在Worker node上. + remote read: 要執行Reduce程式的Worker node,要從這些在不同位置的Worker node上,下載屬於它要執行的中間資料,作為Reduce程式的input。而遠端讀取中間資料的過程分成三階段:copy(shuffle)->sort->reduce
- write: 最後將使用者需要的運算結果輸出。
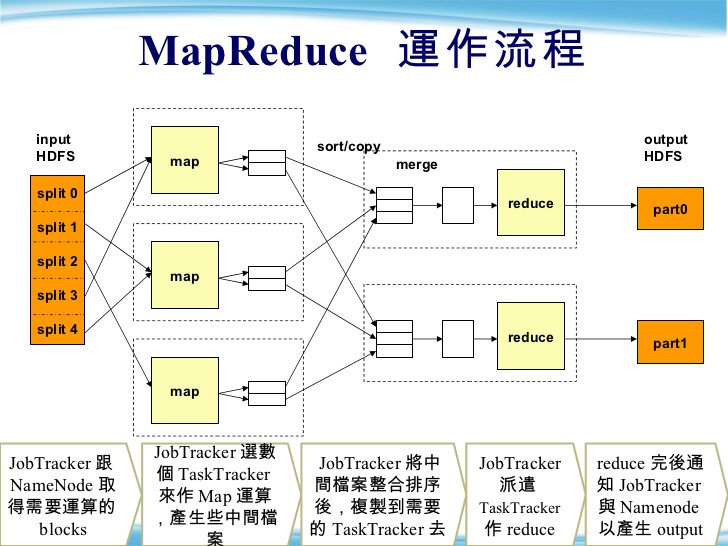
split input
- 平行化程式要執行的輸入檔案通常資料量相當大,因此必須將資料切割成許多資料區塊,每個資料區塊稱為split或shard。
- 如果有個map workers,就會將原本的資料至少切成塊,這樣每個map worker都有事情做,也可以切成更多塊,但就會變成要分到下一批執行,Master node會負責分配每個map worker要執行的split數目。
- 在Hadoop中,map task的個數主要是由總輸入檔案大小除以每個split檔案大小來決定的。
- 舉例來說,input為一個500MB的檔案,而每個split檔案大小預設為64MB,Hadoop會自動產生8個map task.
- 但map worker的個數是有限制的,這部分的設定是與硬體資源(CPU core個數)有關
- Ex: 2個Hadoop node=2個tasktracker,預設最多只能同時執行4個map task,因為每個node的最大map task數量預設為2,但map task的總個數仍有個參考參數可調整
fork process
- Master node負責發送job給workers,並追蹤執行的進度及回傳結果。
- Master node會選擇目前空閒的worker node,指定他要執行map task或reduce task。
- 一個map task只會處理原本輸入資料的其中一個shard部份,reduce task則處理map task執行完後產生的中間資料。
- worker會接收master的訊息,決定執行map或reduce task,還有要去哪裡讀哪些資料做為input。
map
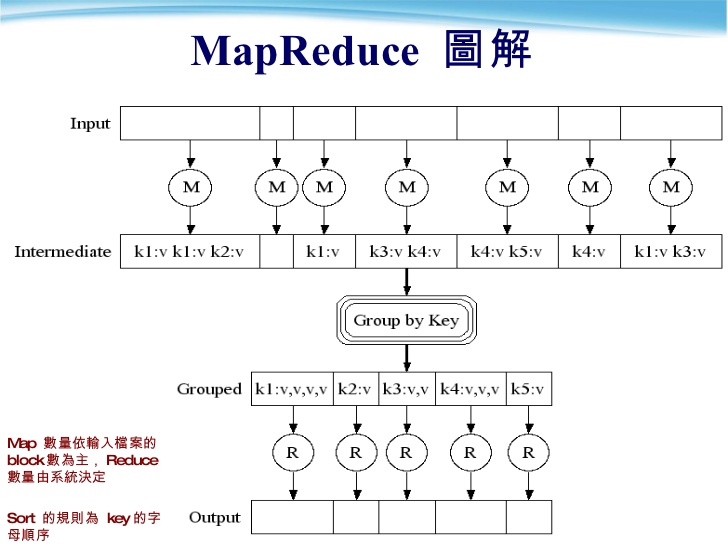
每個map task會從input shard中讀取指派給他執行的資料,並將有興趣需要處理的資料parse成(key,value) pairs,map function會在此丟棄很多沒有興趣處理的資料,也就是map function抓到它要的input後,執行完function內的程式,intermediate files就是程式內撰寫的輸出結果,當然其他的資料就會被丟棄。
藉由許多map worker同時執行,提升performance。
Map Worker: Partition
map worker執行完map function內的程式後,最後的output仍是(key,value)這個資料串,這些中間資料會先緩存在記憶體中,並階段性的存到map worker的本機硬碟上。
- 當map的輸出超過一定的臨界值 ex.80MB,就必須將記憶體buffer內的資料寫成一個檔案暫存在本機硬碟,不然buffer會爆炸呀,新的map輸出也進不來,而這個過程就叫做spill,當然,每個spill內的map輸出們,都會先照key做排序
spill的過程,是由background thread來執行,因此同時間map function的輸出仍會持續產生
若map執行完後有多個spill檔,最後還會進行merge,將所有spill檔merge成一個,如何將spill檔做merge可由Combiner function決定。
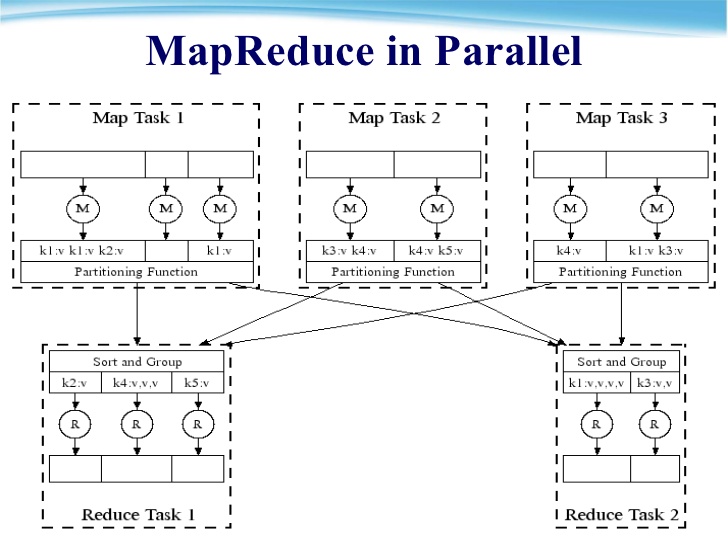
merge完的這個中間資料檔案,會由Partition function分割成R個區域,partition function負責決定R個reduce workers中,哪些人負責處理哪些key的資料,預設的partition function是單純將key值除以R取餘數做hash,使用者如果要指定哪些key的資料給哪台reduce worker執行,可以在此修改partition function。
reduce: sort(shuffle)
當所有map worker的工作完成時,Master node就會通知Reduce workers開始工作。
Reduce workers第一件要做的事,就是拿到reduce function要執行的input資料,reduce worker會透過remote procedure calls,向map worker拿屬於這個reduce worker要處理的partition中的(key,value)資料,而這些資料一樣會透過key進行排序。
排序是必須的動作,因為資料可能會有相同的key值,若無排序會發生很多不同key值的資料卻散亂的分給同一個reduce worker(即是在同一個partition)。
排序完成後,目的是把所有有相同key值的資料聚集在一起,也容易抓取有相同key值的所有資料。
而這個階段也稱做Shuffle。
reduce function
當資料照key值排序好後,user寫的reduce function就可以開始執行。
每當讀入一個新的key值時,reduce worker就會呼叫一次reduce function,這個function會傳入兩個參數,1. key值 2. 所有有相同key的value組成的list。
執行完reduce function內要做的運算後,將output寫入記憶體,output仍為(key,value)型態。
output
當所有reduce worker完成工作,Master會將控制權轉回user program,MapReduce的輸出會存成R個輸出檔(在Hadoop中可看到輸出為part_XX..),分別就是由R個reduce worker創建的。
*