HDFS - Hadoop Distributed File System (HDFS)
- HDFS(Hadoop Distributed File System)是Yahoo提出的Hadoop內部所使用的一套分散式檔案系統,可將一整個叢集(Cluster)視為一台電腦,進行檔案存取的操作。
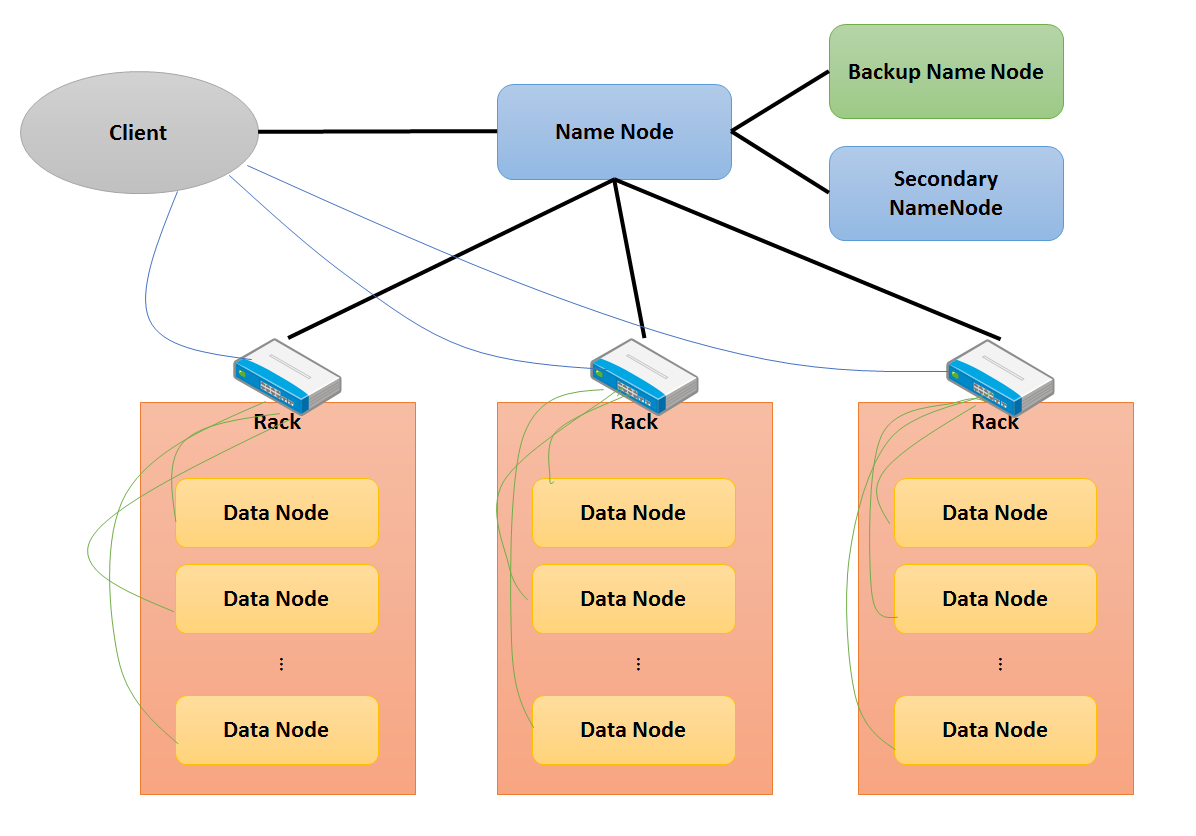
- HDFS架構主要由幾個重要元件所組成。
Name Node
- Name Node(NN)為HDFS的核心元件,管理整個HDFS(檔案讀取寫入...等操作)。整個Cluster中只有一個NN,故為Single Point of Failure,也就是說NN本身沒有HA(High Availability),所以當Name Node掛掉後,整個HDFS會Crash。NN會儲存檔案系統內的所有檔案的Metadata,包含擁有者, 權限, 檔案各Block位置...等。另外,它會將HDFS狀態存成Snapshot(檔名為fsimage)放置在NN local的硬碟中,並且將Metadata變更存在硬碟上的edit log檔案裡,但其實Metadata更新都會再Memory裡完成,只是更新紀錄會寫入edit log。究竟fsimage與edit log有什麼用呢,在Secondary NameNode就會提到。
Secondary NameNode
- Secondary NameNode(SN)乍聽之下好像是Name Node的分身一樣,其實他與NN是完全不同的東西,所以當NN掛掉的時候,它不能拿來當NN,這點必須注意。那SN到底用來幹嘛用的?在說明之前先講解NN那部分提到的Metadata更動的部分。其實NN使用一種特殊的機制來進行Metadata的更動。NN在一開始啟動的時候會讀取fsimage HDFS的狀態進Memory,然後一一讀取edit log上所記錄的變更,一步一步將Memory中的HDFS狀態在Memory中Roll Back達到狀態的更新,此時edit log檔案會被全新空白的edit log檔案覆蓋,舊的fsimage檔案也會被新的覆蓋。重點就是這個,因為這個動作只有在一開始的時候做,所以可想而知,edit log會愈長愈肥,接著下次NN重開的時候,就會超久。SN就是為了解決這個問題,它會定期從NN那下載fsimage與edit log,然後將這兩個合併,再傳回去給NN覆蓋,自己也保留一份備份,這樣就可以減少NN的負擔。因為SN要執行這大量的Memory操作,所以建議Memory大小與NN相同。在這裡再次提醒,SN進行的動作只是為NN建立一個還原點,所以如果NN掛掉,SN是無法取代NN執行的。
Backup Name Node
- Backup Name Node(BN)的功能就和NN完全一樣了,另外他也進行SN的工作,一來可以替NN建立還原點,二來當NN掛掉的時候BN可以馬上起來接替NN進行動作,角色轉為NN,而原來的NN重新啟動後就會轉成BN。在HDFS架構中,BN是個選擇性的存在,因為它的功能與NN, SN重複,但建議還是用BN取代SN以達到NN的HA。
Data Node
- Data Node(DN)主要就是資料儲存的節點,儲存方式以Block為單位,一個檔案在HDFS上進行儲存時,會被按照固定大小(預設為64MB)分割成許多個Block,而這些Block分別儲存在不同DN的硬碟上,所以雖然使用者在介面上看到只有一個檔案,但這個檔案的資料其實是分布在整個Cluster中。另外,DN會保持與NN的聯繫,所以當DN掛掉的時候,NN會知道這個DN已經死了。DN也是實際上對Block進行操作的節點,NN發出指令後,DN對Block執行NN的指令,像複製, 刪除, 修改...等。