彈性分散式資料集(RDD, Resilient Distributed Dataset)
通常來講,針對資料處理有幾種常見模型,包括:iterative algorithms,relational queries,mapreduce,stream processing。
- Hadoop MapReduce採用了MapReduces模型。
- RDD混合了這四種模型,使得Spark可以應用於各種大資料處理場景。
在某些運算或演算法執行下 MapReduce 就顯得不夠力,舉例最知名的兩個場景:
- 迭代式算法(Iterative algorithm) : 如:機器學習演算法, 分類演算法 (這類演算法要不斷執行同個步驟 且每個步驟以上個結果為輸入)
交互式分析(Iterative Analyst) : 如:Markov chain (求長遠時間之後的平衡狀態為何)
為什麼MapReduce不適合執行上述之場景呢?,因為 MapReduce 執行過程中 必須將工作的結果存回HDFS中,但是在需要不斷運算的場景下 (像是要重複算上萬次得到結果) 這一來一往的I/O將十分龐大,原因其實是 MapReduce一開始就不是為了這些場景而去設計的 自然會有這些問題,其實是我們的需求增加而產生這樣的問題。

上述問題讓人們發現MapReduce缺少一個重要的要素,有效的資料共享(efficient data sharing)而Spark即提出一個能解決的問題的效果,即In-Memory Data Processing and Sharing。
巨量資料可分為以下三種狀況:
- 複雜的批次處理資料(batch data processing):時間長,跨度為10min ~ N hr.
- 以歷史資料為基礎的互動查詢(interactive query): 時間通常為10sec ~ N min.
- 以即時資料流為基礎的資料處理(streaming data processing): 時間跨度通常為 N ms ~ N sec.

若是能將中間運算結果直間存於Memory 中 那自然就會快速許多而要如何設計一個高容錯(tolerant) 高效能(efficient)的結構?這是RDD的設計概念由來Resilient Distribute Datasets。
所謂的RDD,乃是由AMPLab實驗室所提出的概念,類似一種分散式的記憶體。而且,RDD是一種可跨群集(cluster)被使用、可儲存於主記憶體中的immutable的物件集合。這裡所謂的immutable物件,乃是指在被產生之後,其狀態便無法被修改的物件。
使用RDD的一般場景:
- 你需要使用low-level的transformation和action來控制你的資料集;
- 資料集非結構化,比如,流媒體或者文本流;
- 你想使用函數式編程來操作資料,而不是用特定領域語言(DSL)表達;
- 你不在乎schema,比如,當通過名字或者列處理(或訪問)資料屬性不在意列式存儲格式;
- 放棄使用DataFrame和Dataset來優化結構化和半結構化資料集

- 照官方文件說法 實際上一個RDD會有五種資料。前三項在RDD概念裡主要是為了實現血統關係(lineage),主要是為了容錯而設計。
- 每個partition位置 (set of partitions)
- 與parent RDD的依賴關依(list of dependcies on parent RDDs)
- parent RDD經過何種運算得到此RDD (function to compute a partition) given its parent(s)
- (optional) partitioner(hash, range)
- (optional) preferred locations for each partition.
計算方式
RDD有三種運算方式:
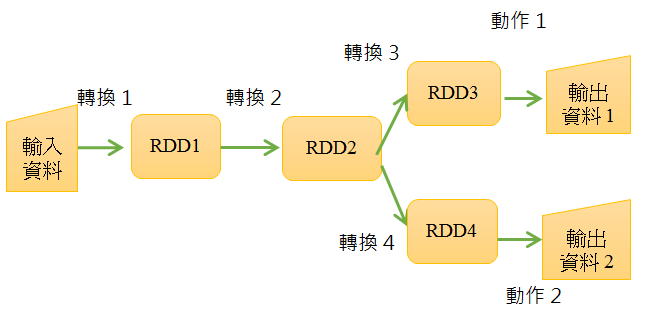
- 轉換(Transformation): 懶惰(lazy)運算 會製造出新的RDD
- 動作(Action): 執行一個運算並return結果或是存到Storage裡
- 持久化(Persistent): 對於會重複使用的RDD,可以將RDD持久化在記憶體中做為後續使用,以加快效能。
換句話說,「轉換」的結果,是在RDD的計算世界中,而「動作」的結果,則是輸出至此世界之外。所以,當我們產生RDD物件進到計算世界中之後,可以對其施加多次的「轉換」,當一旦於其上執行「動作」之後,就會從此計算世界中,得到真正可使用的計算結果了。
- RDD透過「轉換」操作可以得出新的轉換,但Spark會延遲這個「轉換」動作的發生時間點,它並不會馬上執行,而是等到的確需要得出某個值時,才會基於所有的RDD關係來執行轉換。
- RDD本身有個Lineage機制,也就是說,它會維持每個RDD與其父代RDD reference之間的關聯,以及究竟是透過什麼操作,才由父代RDD得到該RDD的資訊。
- 也正因為有了Lineage機制,以及RDD本身先天的immutable特性,使得它具備了容錯的特性,即使特定節點損毀,儲存於其上的RDD也能重新計算得出,因而避免了特定節點損毀就無法運作的問題。
- 不論是「轉換」或是「動作」,基本上,都是以函數式(functional)的形式來表述。因此,正如前一回中所提到的,這種方式很適合「divide-and-conquer」的解題方式。
- lazy load的機制的優點是可以最佳化。例如我們要從一個非常大的資料檔案,讀取資料並篩選欄位,但是最後只要顯示前10筆資料。
- 如果沒有lazy機制,就必須讀取整個檔案處理,會花很多時間與記憶體。
- 有了lazy機制後,由於事先已知道所有轉換與動作,系統知道只須顯示前10筆資料,因此只要讀取部份資料,篩選欄位即可,節省許多計算資源。

RDD的缺點
- RDD的主要缺點:
- 操作與使用方法不夠友善。
- 使用上必須要有map/reduce的概念。
- RDD沒有定義schema(即未定義欄位名稱與資料型態),我們只能用位置來指定每一個欄位,如同array一般。此問題可由spark的dataframe或SQL解決。