Apache spark
Apache Spark是一個大資料處理框架。最初在2009年由加州大學伯克利分校的AMPLab開發,並于2010年成為Apache的開源項目之一。
Grid computing如MPI, PVM等的目的是著重在分散工作量(CPU-bounded task),而處理大資料的重點在於分散資料量後再個別處理。
分散大量資料的困難點在於:
- 交換資料須同步處理:死結(deadlock)問題。
- 有限的網路頻寬
Hadoop和Spark
Hadoop這項大資料處理技術大概已有十年歷史,而且被看做是首選的大資料集合處理的解決方案。MapReduce是一路計算的優秀解決方案,不過對於需要多路計算和演算法的用例來說,並非十分高效。資料處理流程中的每一步都需要一個Map階段和一個Reduce階段,而且如果要利用這一解決方案,需要將所有用例都轉換成MapReduce模式。
在下一步開始之前,上一步的作業輸出資料必須要存儲到分散式檔案系統中。因此,複製和磁片存儲會導致這種方式速度變慢。另外Hadoop解決方案中通常會包含難以安裝和管理的集群。而且為了處理不同的大資料用例,還需要集成多種不同的工具(如用於機器學習的Mahout和流資料處理的Storm)。
如果想要完成比較複雜的工作,就必須將一系列的MapReduce作業串聯起來然後循序執行這些作業。每一個作業都是高時延的,而且只有在前一個作業完成之後下一個作業才能開始啟動。 而Spark則允許程式開發者使用有向無環圖(DAG)開發複雜的多步資料管道。而且還支援跨有向無環圖的記憶體資料共用,以便不同的作業可以共同處理同一個資料。 Spark運行在現有的Hadoop分散式檔案系統基礎之上(HDFS)提供額外的增強功能。它支持將Spark應用部署到現存的Hadoop v1集群(with SIMR – Spark-Inside-MapReduce)或Hadoop v2 YARN集群甚至是Apache Mesos之中。
我們應該將Spark看作是Hadoop MapReduce的一個替代品而不是Hadoop的替代品。其意圖並非是替代Hadoop,而是為了提供一個管理不同的大資料用例和需求的全面且統一的解決方案。

Spark特性
- Spark通過在資料處理過程中成本更低的洗牌(Shuffle)方式,將MapReduce提升到一個更高的層次。利用記憶體資料存儲和接近即時的處理能力,Spark比其他的大資料處理技術的性能要快很多倍。
- Spark還支援大資料查詢的延遲計算,這可以説明優化大資料處理流程中的處理步驟。Spark還提供高級的API以提升開發者的生產力,除此之外還為大資料解決方案提供一致的體系架構模型。
- Spark將中間結果保存在記憶體中而不是將其寫入磁片,當需要多次處理同一資料集時,這一點特別實用。Spark的設計初衷就是既可以在記憶體中又可以在磁片上工作的執行引擎。當記憶體中的資料不適用時,Spark操作符就會執行外部操作。Spark可以用於處理大於集群記憶體容量總和的資料集。
- Spark會嘗試在記憶體中存儲盡可能多的資料然後將其寫入磁片。它可以將某個資料集的一部分存入記憶體而剩餘部分存入磁片。開發者需要根據資料和用例評估對記憶體的需求。Spark的性能優勢得益於這種記憶體中的資料存儲。
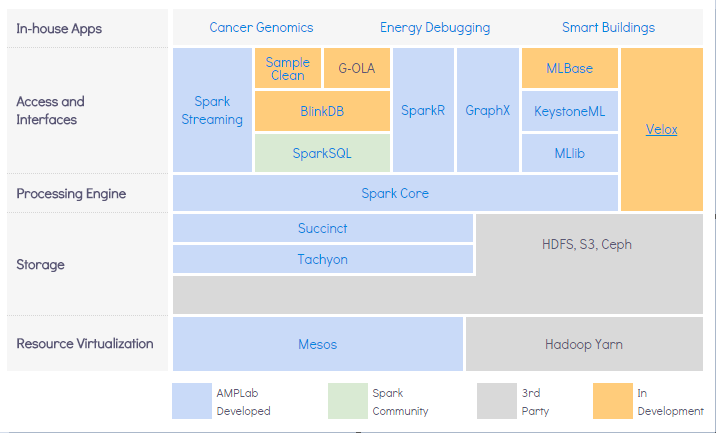
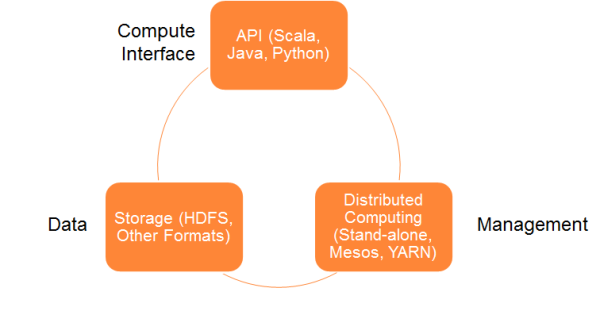
Spark體系架構
Spark體系架構包括如下三個主要組件:
資料存儲
- Spark用HDFS檔案系統存儲資料。它可用于存儲任何相容於Hadoop的資料來源,包括HDFS,HBase,Cassandra等。
API
- 利用API,應用開發者可以用標準的API介面創建基於Spark的應用。Spark提供Scala,Java和Python三種程式設計語言的API。
管理框架
- Spark既可以部署在一個單獨的伺服器也可以部署在像Mesos或YARN這樣的分散式運算框架之上。
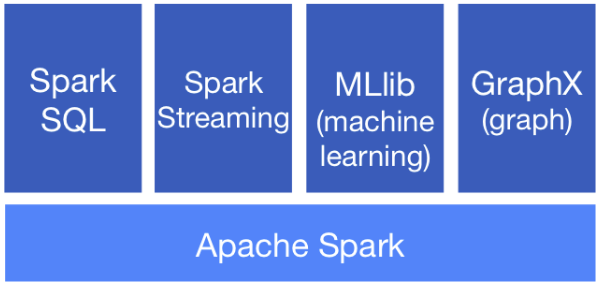
- Spark元件如下:
| 功能 | 說明 |
|---|---|
| Spark SQL | Spark SQL可使用SQL查詢語法,執行資料分析 |
| Spark streaming | 可達成即時資料串流的處理,具有高資料量、可容錯性、可擴充性等特點 |
| GraphX | 為Spark上的分散式圖形處理架構,可做圖表分析 |
| MLlib | 可擴充的Spark機器學習庫,可使用許多常見的機器學習演算法 |
分布式部署

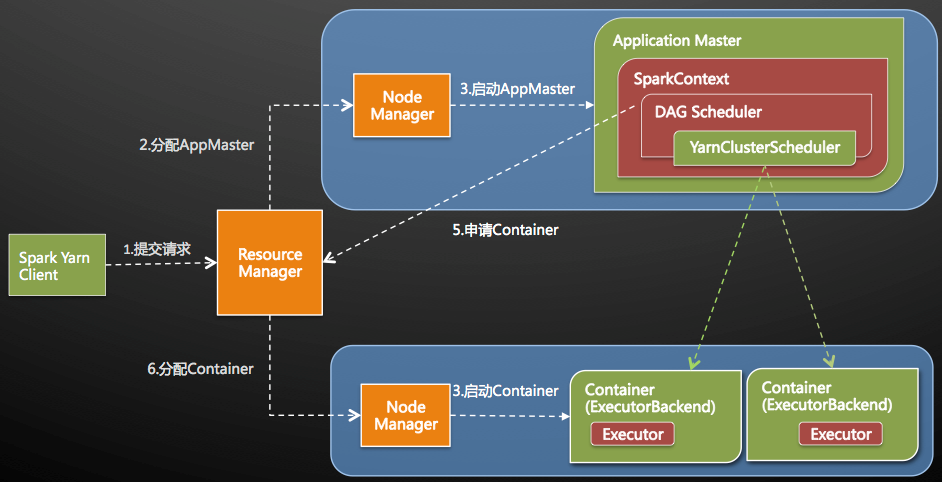
Driverprogram就是自行設計的Spark程式,在程式中必須定義SparkContext,其為開發Spark應用程式的入口。
- SparkContext透過Cluster manager來管理整個集群,而集群中包含了許多的Worker node, 在每一個worker node都有executor負責執行任務。
- SparkConext透過Cluster manager來管理整個集群的優點是所設計的Spark可切換在不同的cluster模式。
Cluster manager可執行在以下部署方式:
- Local machine:直接在本機執行
- Standalone Deploy Mode:spark提供的cluster管理模式。
- Amazon EC2:Amazon提供的雲端機器
- Hadoop YARN:Hadoop 2.x所提供的資源管理方式
- Apache Mesos
YARN與Mesos的比較可見此篇blog.
standalone模式
即獨立模式,自帶完整的服務,可單獨部署到一個集群中,無需依賴任何其他資源管理系統。從一定程度上說,該模式是yarn與mesos的基礎。
我們可以得到一種開發新型計算框架的一般思路:先設計出它的standalone模式,為了快速開發,起初不需要考慮服務(比如master/slave)的容錯性,之後再開發相應的wrapper,將stanlone模式下的服務原封不動的部署到資源管理系統yarn或者mesos上,由資源管理系統負責服務本身的容錯。目前Spark在standalone模式下是沒有任何單點故障問題的。
將Spark standalone與MapReduce比較,會發現它們兩個在架構上是完全一致的:
- 都是由master/slaves服務組成的,且起初master均存在單點故障,後來均通過zookeeper解決
- 各個節點上的資源被抽象成粗細微性的slot,有多少slot就能同時運行多少task。不同的是,MapReduce將slot分為map slot和reduce slot,它們分別只能供Map Task和Reduce Task使用,而不能共用,這是MapReduce資源利率低效的原因之一,而Spark則更優化一些,它不區分slot類型,只有一種slot,可以供各種類型的Task使用,這種方式可以提高資源利用率,但是不夠靈活,不能為不同類型的Task定制slot資源。總之,這兩種方式各有優缺點。

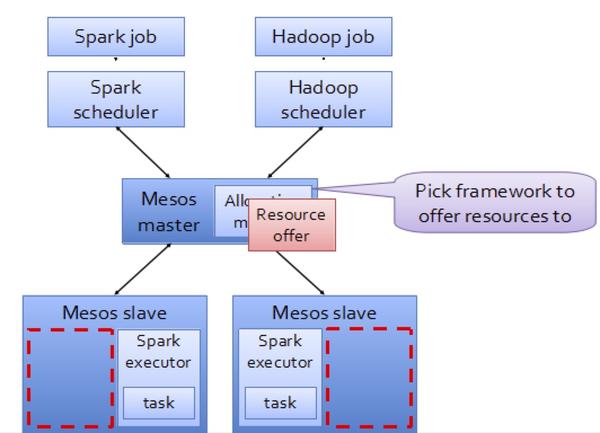
Mesos模式
Spark On Mesos模式。這是很多公司採用的模式,官方推薦這種模式(當然,原因之一是血緣關係)。正是由於Spark開發之初就考慮到支援Mesos。
目前在Spark On Mesos環境中,使用者可選擇兩種調度模式之一運行自己的應用程式:
粗細微性模式(Coarse-grained Mode):每個應用程式的運行環境由一個Dirver和若干個Executor組成,其中,每個Executor佔用若干資源,內部可運行多個Task(對應多少個“slot”)。應用程式的各個任務正式運行之前,需要將運行環境中的資源全部申請好,且運行過程中要一直佔用這些資源,即使不用,最後程式運行結束後,回收這些資源。
細細微性模式(Fine-grained Mode):鑒於粗細微性模式會造成大量資源浪費,Spark On Mesos還提供了另外一種調度模式:細細微性模式,這種模式類似於現在的雲計算,思想是按需分配。與粗細微性模式一樣,應用程式啟動時,先會啟動executor,但每個executor佔用資源僅僅是自己運行所需的資源,不需要考慮將來要運行的任務,之後,mesos會為每個executor動態分配資源,每分配一些,便可以運行一個新任務,單個Task運行完之後可以馬上釋放對應的資源。每個Task會彙報狀態給Mesos slave和Mesos Master,便於更加細細微性管理和容錯,這種調度模式類似于MapReduce調度模式,每個Task完全獨立,優點是便於資源控制和隔離,但缺點也很明顯,短作業運行延遲大。
Yarn模式
- 這是一種最有前景的部署模式。但限於YARN自身的發展,目前僅支援粗細微性模式(Coarse-grained Mode)。這是由於YARN上的Container資源是不可以動態伸縮的,一旦Container啟動之後,可使用的資源不能再發生變化,不過這個已經在YARN計畫了。