Nvidia CUDA
CUDA 是 Nvidia 的平行運算架構,可運用繪圖處理單元 (GPU) 的強大處理能力,大幅增加運算效能。
OpenCL與CUDA是功能相似的技術,但由於CUDA提供的工具與解決方案較完整,因此將以CUDA為主做GPU計算的功能筆記。
不同的Nvidia顯示卡支援的CUDA版本功能不同,詳見Nvidia提供的列表。
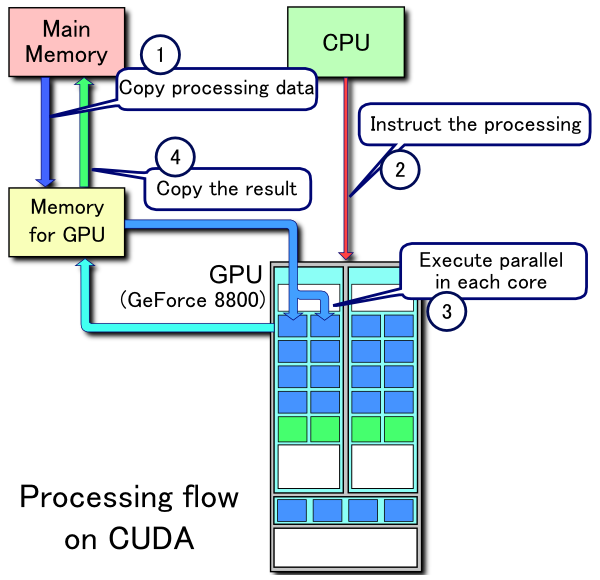
現代的顯示晶片已經具有高度的可程式化能力,由於顯示晶片通常具有相當高的記憶體頻寬,以及大量的執行單元,因此開始有利用顯示晶片來幫助進行一些計算工作的想法,即 GPGPU (general purpose graphical processing unit)。CUDA 即是 NVIDIA 的 GPGPU 模型。
GPGPU的優點
- 顯示晶片通常具有更大的記憶體頻寬。
- 顯示晶片具有更大量的執行單元。
- 和高階 CPU 相比,顯示卡的價格較為低廉。
GPGPU的缺點
- 顯示晶片的運算單元數量很多,因此對於不能高度平行化的工作,所能帶來的幫助就不大。
- 顯示晶片目前通常在浮點數單精度(32-bit)的性能較佳,且多半不能完全支援 IEEE 754 規格, 有些運算的精確度可能較低。目前許多顯示晶片並沒有分開的整數運算單元,因此整數運算的效率較差。
- 顯示晶片通常不具有分支預測等複雜的流程控制單元,因此對於具有高度分支的程式,效率會比較差。
整體來說,顯示晶片的性質類似 stream processor,適合一次進行大量相同的工作(如SIMD的流程)。CPU 則比較有彈性,能同時進行變化較多的工作。
CUDA 架構
* 在 CUDA 的架構下,一個程式分為兩個部份:host 端和 device 端。Host 端是指在 CPU 上執行的部份,而 device 端則是在顯示晶片上執行的部份。Device 端的程式又稱為 "kernel"。通常 host 端程式會將資料準備好後,複製到顯示卡的記憶體中,再由顯示晶片執行 device 端程式,完成後再由 host 端程式將結果從顯示卡的記憶體中取回。
由於 CPU 存取顯示記憶體時只能透過 PCI Express 介面(目前顯示卡均使用PCI express架構,以後也許會使用更快的介面),因此速度較慢(PCI Express x16 的理論頻寬是雙向各 4GB/s),因此不能太常進行這類動作,以免降低效率。
在 CUDA 架構下,顯示晶片執行時的最小單位是 thread。數個 thread 可以組成一個 block 。一個 block 中的 thread 能存取同一塊共用的記憶體,而且可以快速進行同步的動作。(類似同一個process下的thread可以共享記憶體)。
每一個 block 所能包含的 thread 數目是有限的。不過,執行相同程式的 block,可以組成 grid。不同 block 中的 thread 無法存取同一個共用的記憶體,因此無法直接互通或進行同步。因此,不同 block 中的 thread 能合作的程度是比較低的。不過,利用這個模式,可以讓程式不用擔心顯示晶片實際上能同時執行的 thread 數目限制。例如,一個具有很少量執行單元的顯示晶片,可能會把各個 block 中的 thread 循序執行,而非同時執行。不同的 grid 則可以執行不同的程式(即 kernel)。
每個 thread 都有自己的一份 register 和 local memory 的空間。同一個 block 中的每個 thread 則有共用的一份 share memory。此外,所有的 thread(包括不同 block 的 thread)都共用一份 global memory、constant memory、和 texture memory。不同的 grid 則有各自的 global memory、constant memory 和 texture memory。
執行模式
由於顯示晶片大量平行計算的特性,它處理一些問題的方式,和一般 CPU 是不同的。主要的特點包括:
記憶體存取 latency 的問題:CPU 通常使用 cache 來減少存取主記憶體的次數,以避免記憶體 latency 影響到執行效率。顯示晶片則多半沒有 cache(或很小),而利用平行化執行的方式來隱藏記憶體的 latency(即,當第一個 thread 需要等待記憶體讀取結果時,則開始執行第二個 thread,依此類推)。
分支指令的問題:CPU 通常利用分支預測等方式來減少分支指令造成的 pipeline bubble。顯示晶片則多半使用類似處理記憶體 latency 的方式。不過,通常顯示晶片處理分支的效率會比較差。
因此,最適合利用 CUDA 處理的問題,是可以大量平行化的問題,才能有效隱藏記憶體的 latency,並有效利用顯示晶片上的大量執行單元。使用 CUDA 時,同時有上千個 thread 在執行是很正常的。因此,如果不能大量平行化的問題,使用 CUDA 就沒辦法達到最好的效率了。
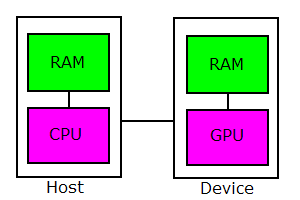
主機與裝置(host and device)
區分主機和裝置的不同:
- 主機就是PC。
- 裝置就是顯示卡。
兩者皆有中央處理器,主機上為 CPU,裝置上為 GPU,指令集不同:
- 主機上的程式碼使用傳統 C/C++ 語法撰寫成,實作與呼叫和一般函式無異,
- 裝置上的程式碼稱為【核心】(kernel),需使用 CUDA 的延伸語法 (函式前加global 等標籤) 來撰寫,並於呼叫時指定執行緒群組大小。
兩者皆有各自的記憶體(DRAM),擁有獨立的定址空間:
- 主機上的透過 malloc()、free()、new、delete 等函式配置與釋放,
- 裝置上的透過 cudaMalloc()、cudaFree() 等 API 配置與釋放,
因為主機和裝置的不同,C/C++ 的標準函式庫不能在 kernel 中直接使用,例如要秀出計算結果,必需使用 cudaMemcpy() 先將資料搬移至主機,再呼叫 printf 或 cout 等標準輸出函式。主機和裝置之間的資料搬移,使用 cudaMemcpy() 這個 API。
使用時先在主機記憶體設好資料的初始值,然後傳入裝置記憶體,接著執行核心,如果可以的話就儘量讓資料保留在裝置中,進行一連串的 kernel 操作,避免透過 PCI-E 搬移造成效能下降,最後再將結果傳回主機中顯示。
使用 API 配置裝置記憶體與主機和裝置間資料搬移
- 最基本的 API 有 5 個 (in cuda.h):
- 配置裝置記憶體: cudaMalloc()
- 釋放裝置記憶體: cudaFree()
- 記憶體複制: cudaMemcpy()
- 錯誤字串解譯: cudaGetErrorString()
- 同步化: cudaThreadSynchronize()
配置顯示記憶體 cudaMalloc()
cudaError_t cudaMalloc(void** ptr, size_t count);
- ptr指向目的指位器之位址m,count 欲配置的大小(單位 bytes)
- 傳回值 cudaError_t 是個 enum, 執行成功時傳回 0, 其他的錯誤代號可用cudaGetErrorString() 來解譯.
釋放顯示記憶體 cudaFree()
cudaError_t cudaFree(void* ptr);
- ptr指向欲釋放的位址 (device memory)
記憶體複制 cudaMemcpy()
cudaError_t cudaMemcpy(void* dst, const void* src, size_t count,
enum cudaMemcpyKind kind);
- dst: 指向目的位址,src:指向來源位址,count 拷貝區塊大小 (單位 bytes)
- kind 有四種拷貝流向
- cudaMemcpyHostToHost 主機 -> 主機
- cudaMemcpyHostToDevice 主機 -> 裝置
- cudaMemcpyDeviceToHost 裝置 -> 主機
- cudaMemcpyDeviceToDevice 裝置 -> 裝置
- kind 有四種拷貝流向
錯誤字串解譯 cudaGetErrorString()
const char* cudaGetErrorString(cudaError_t error);
- 傳回錯誤代號(error)所代表的字串
同步化 cudaThreadSynchronize()
cudaError_t cudaThreadSynchronize(void);
用來進行核心和主機程序的同步。
#include<stdio.h>
#include<cuda.h>
int main(){
const int num=100;
int* g;
cudaError_t r;
//主機陣列 & 初始化
int a[num], b[num];
for(int k=0; k<num; k++){
a[k]=k;
b[k]=0;
}
//配置裝置記憶體 & 顯示錯誤訊息
r=cudaMalloc((void**) &g, sizeof(int)*num);
printf("cudaMalloc : %s\n",cudaGetErrorString(r));
//複制記憶體: 主機記憶體 a[] ------> 裝置記憶體 g[]
r=cudaMemcpy(g, a, sizeof(int)*num, cudaMemcpyHostToDevice);
printf("cudaMemcpy a => g : %s\n",cudaGetErrorString(r));
//複制記憶體: 裝置記憶體 g[] ------> 主機記憶體 b[]
r=cudaMemcpy(b, g, sizeof(int)*num, cudaMemcpyDeviceToHost);
printf("cudaMemcpy g => b : %s\n",cudaGetErrorString(r));
//結果比對
bool ooo=true;
for(int k=0; k<num; k++){
if(a[k]!=b[k]){
ooo=false;
break;
}
}
printf("check a==b? : %s\n",ooo?"pass":"wrong");
//釋放裝置記憶體
r=cudaFree(g);
printf("cudaFree : %s\n",cudaGetErrorString(r));
return 0;
}
- 執行結果:
cudaMalloc : no error cudaMemcpy a => g : no error cudaMemcpy g => b : no error check a==b? : pass cudaFree : no error
函式與呼叫 (主機、裝置)
- CUDA 中,主機函式的寫法與呼叫和傳統 C/C++ 無異,而裝置核心 (kernel) 要使用延伸語法:
__global__ void 函式名稱 (函式引數...){ ...函式內容... }; 多了 global 這標籤來標明這道函式是核心程式碼,要編譯器特別照顧一下,注意事項如下:
- 傳回值隻能是 void (要傳東西出來請透過引數)
- 裏面不能呼叫主機函式或 global 函式 (這兩者皆是主機用的)
- 輸入的資料若是位址或參考時,必需指向裝置記憶體。
用來指定 function 是要在 host 或 device 上執行,以及是用來被 host 或 device 呼叫。他的類別有三種: +device
- 在 device 上執行,且只能被 device 呼叫。 - 同時,他永遠是 inline function。+global
- 將 function 宣告成一個 kernel,在 device 上執行,只能被 host 呼叫。 - 他的 return type 必須要是 void;傳入的參數會是透過 shared memory 給 device- host
- 在 host 上執行,且只能被 host 呼叫。(相當於一般的 function)
- host
而在 device 上執行的function(device 和 global)有一些基本的限制:
- 不支援遞迴
- 不能有 static 變數
- 不能使用 variable number of arguments
呼叫 kernel 函式的語法比一般 C 函式多了指定網格和區塊大小的序:
函式名稱 <<<網格大小, 區塊大小, (shared memory大小(可忽略))>>> (函式引數...);
#include<stdio.h>
#include<cuda.h>
//裝置函式(核心) 在顯示卡記憶體中填入 hello CUDA 字串
__global__ void hello(char* s){
char w[50]="hello CUDA ~~~ =^.^=";
int k;
for(k=0; w[k]!=0; k++)
s[k]=w[k];
s[k]=0;
};
//主機函式
int main(){
char* d;
char h[100];
//配置裝置記憶體
cudaMalloc((void**) &d, 100);
//呼叫裝置核心 (隻使用單一執行緒)
hello<<<1,1>>>(d);
//下載裝置記憶體內容到主機上
cudaMemcpy(h, d, 100, cudaMemcpyDeviceToHost);
//顯示內容
printf("%s\n", h);
//釋放裝置記憶體
cudaFree(d);
return 0;
}
變數修飾字
- 在變數類型方面,是用來指定記憶體的類型。分成三種:
- device
- 宣告變數存在 device 上;可以和下面兩者同時使用,來做更進一步的設定。如果沒有額外指定的話,那這個變數
- 會存在 global memory 空間
- 生命週期和程式相同
- 可以被 grid 中的所有 thread 透過 runtime library 存取。
- 宣告變數存在 device 上;可以和下面兩者同時使用,來做更進一步的設定。如果沒有額外指定的話,那這個變數
- constant
- 可和 device 同時使用,會將變數宣告成
- 存在 constant memory 空間
- 生命週期和程式相同
- 可以被 grid 中的所有 thread 透過 runtime library 存取。
- 可和 device 同時使用,會將變數宣告成
- shared
- 可和 device 同時使用,會將變數宣告成:
- 存在 thread block 的 shared memory 空間
- 生命週期和 thread block 相同
- 只能被 block 中的 thread 存取
- 可和 device 同時使用,會將變數宣告成:
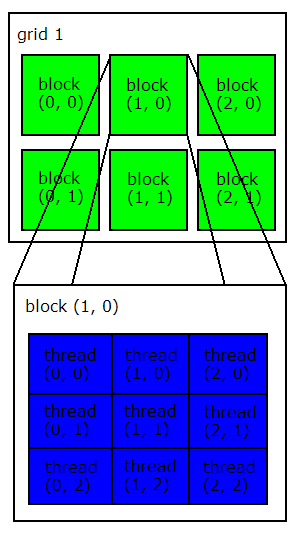
網格、區塊、執行緒(grid, block and thread)
GPU 是具備超多核心,能行大量平行化運算的晶片,執行緒眾多,要分群組管理:
- 最基本的執行單位是執行緒(thread),
- 數個執行緒組成區塊(block),
- 數個區塊組成網格(grid),
- 整個網格就是所謂的核心(kernel)。
執行緒是最基本的執行單位,程式設計師站在執行緒的角度,透過內建變數,定出執行緒的位置,對工作進行主動切割。
區塊為執行緒的群組,一個區塊可包含 1~512 個執行緒,
- 每個執行緒在區塊中擁有唯一的索引編號,記錄於內建變數 threadIdx。
- 每個區塊中包含的執行緒數目,記錄於內建變數 blockDim。
- 相同區塊內的執行緒可同步化,而且可透過共享記憶體交換資料
網格為區塊的群組,一個網格可包含 1~65535 個區塊,
- 每個區塊在網格中擁有唯一的索引編號,記錄於內建變數 blockIdx。
- 每個網格中包含的區塊數目,記錄於內建變數 gridDim。
- 網格中的區塊可能會同時或分散在不同時間執行,視硬體情況而定。
內建唯讀變數 gridDim, blockDim, blockIdx, threadIdx 皆是 3D 正整數的結構體
- uint3 gridDim :網格大小 (網格中包含的區塊數目)
- uint3 blockIdx :區塊索引 (網格中區塊的索引)
- uint3 blockDim :區塊大小 (區塊中包含的執行緒數目)
- uint3 threadIdx:執行緒索引 (區塊中執行緒的索引)
- 其中 uint3 為 3D 的正整數型態,定義如下
struct uint3{ unsigned int x,y,z; }; - 這些唯讀變數只能在核心中使用。
- GRID 的大小雖然是 uint3 的結構,但只能使用 2D 而已(其 z 成員隻能是 1),BLOCK 才能完整支援 3D 結構。
核心呼叫時指定的網格和區塊大小對應的就是其中 gridDim 和 blockDim 兩變數,網格和區塊大小在設定時有一定的限制。
- 網格: max(gridDim) = 65535
- 區塊: max(blockDim) = 512
- 實際在用的時候 blockDim 還會有資源上的限制, 主要是暫存器數目,所以有時達不到 512 這個數量, 在 3 維的情況還會有其他的限制,建議使用 1 維的方式呼叫, 到核心中再去切, 執行緒組態比較簡單,而且 bug 和限制也會比較少。
#include<stdio.h>
#include<cuda.h>
//索引用到的緒構體
struct Index{
int block, thread;
};
//核心:把索引寫入裝置記憶體
__global__ void prob_idx(Index id[]){
int b=blockIdx.x; //區塊索引
int t=threadIdx.x; //執行緒索引
int n=blockDim.x; //區塊中包含的執行緒數目
int x=b*n+t; //執行緒在陣列中對應的位置
//每個執行緒寫入自己的區塊和執行緒索引.
id[x].block=b;
id[x].thread=t;
};
//主函式
int main(){
Index* d;
Index h[100];
//配置裝置記憶體
cudaMalloc((void**) &d, 100*sizeof(Index));
//呼叫裝置核心
int g=3, b=4, m=g*b;
prob_idx<<<g,b>>>(d);
//下載裝置記憶體內容到主機上
cudaMemcpy(h, d, 100*sizeof(Index), cudaMemcpyDeviceToHost);
//顯示內容
for(int i=0; i<m; i++){
printf("h[%d]={block:%d, thread:%d}\n", i,h[i].block,h[i].thread);
}
//釋放裝置記憶體
cudaFree(d);
return 0;
}
記憶體 (主機、裝置、共享、暫存器)
- 基本的記憶體部份,最重要的是區分主機、裝置、共享記憶體以及暫存器,硬體位置和存取速度列於下表:
| 中文名稱 | 英文名稱 | 硬體位置 | 存取速度 |
|---|---|---|---|
| 主機記憶體 | Host Memory | PC 上的 DRAM | 透過 PCI-E, 很慢 |
| 裝置記憶體 | Device Memory | 顯示卡上的 DRAM | 400~600 cycles |
| 共享記憶體 | Shared Memory | 顯示晶片 | 4 cycles issue |
| 暫存器 | Register | 顯示晶片 | 立即 |
這些記憶體的大小、功能和使用方式如下: |名稱| 大小| 功能| 使用方式 | |---|---|---|---| |主機記憶體| 0.5~10GB| 存放傳統的主機資料 | 透過 API| |裝置記憶體| 0.5~10GB| 存放給 GPU 使用資料| kernel 直接存取| |共享記憶體| 16KB/BLOCK| 執行緒之間交換資料 | kernel 直接存取| |暫存器 | 32~64KB/BLOCK| 執行緒的區域變數| kernel 直接存取|
主機記憶體: 就是傳統 C/C++ 使用的變數,可以透過 malloc()、free()、new、delete 等來配置或釋放。
裝置記憶體: 地位和主機記憶體很像,只是主機記憶體是對付 CPU,而裝置記憶體是對付 GPU,兩者間的資料傳送要透過 CUDA 的 API 達成,可以透過 cudaMalloc()、cudaFree() 等函式來配置或釋放,在 CUDA 中,這類的記憶體稱為全域記憶體 (global memory)。
共享記憶體:比較特殊,在傳統的序列化程式設計裡沒有直接的對應,初學者可能要花多一點的時間在這上面,它用在區塊內執行緒間交換資料,只能在 kernel 中使用,宣告時使用 shared 這個標籤,使用時必需同步,以確保資料讀寫時序上的正確性,現階段在每個區塊上最大的容量為 16KB,超過便無法執行或編譯,因為 on chip 的關係,它屬於快速記憶體。
暫存器:kernel 中大部份的區域變數都是以暫存器的型式存放,不需做額外的宣告手序,這些暫存器是區塊中執行緒共享的,也就是如果每個執行緒使用到 8 個暫存器,呼叫這個 kernel 時區塊大小指定為 10,則整個區塊使用到 810=80 個暫存器,若呼叫時指定區塊大小為 50,則整個區塊使用 850=400 個暫存器。
當使用過多的暫存器時 (>32~64KB/BLOCK,看是那個世代的 GPU),系統會自動把一些資料置換到全域記憶體中,導致執行緒變多,但效率反而變慢 (類似作業系統虛擬記憶體的 swap);另一個會引發這種 swap 的情況是在使用動態索引存取陣列,因為此時需要陣列的順序性,而暫存器本身是沒有所謂的順序的,所以系統會自動把陣列置於全域記憶體中,再按索引存取,這種情況建議使用共享記憶體手動避免。
執行緒同步 (網格、區塊)
| 同步化函式 | 使用地點 | 功能 |
|---|---|---|
| __syncthreads() | 核心程序中 | 同步化區塊內的執行緒 |
| cudaThreadSynchronize() | 主機程序中 | 同步化核心和主機程序 |
- 在 kernel 中,使用 __syncthreads() 來進行區塊內的執行緒的同步, 避免資料時序上的問題 (來自不同 threads),時常和共享記憶體一起使用。
- 在主機程序中,使用 cudaThreadSynchronize() 來進行核心和主機程序的同步,它來避免量到不正確的主機時間 (kernel仍未完成就量時間),因為主機的程序和裝置程序預設是不同步的 (直到下載結果資料之前),這個 API可以強迫它們同步。
合併存取
合併存取(coalesced I/O) 是 CUDA 中最基本且最重要的最佳化手段, 因為GPU 的計算能力太強, 使得效能瓶頸卡在顯示記憶體到 GPU 之間的 I/O 上,合併存取可讓多個顯示記憶體的交易合併成一次, 而加速記憶體的存取.
現階段 GPU 在合併存取上是自動發生的, 以半個 warp 為單位(16 個相鄰的執行緒),如果它們的資料位址是連續的, 就會被合併, 所以使用上很簡單, 只要 threadIdx對齊即可, 它可以合併 4, 8, 16 bytes 的資料, 成為一次 or 兩次的交易, 合併成的最大封包長度可為 32, 64, 128 bytes (其中 32 bytes 的封包只有在版本 1.2 以後支援, 避免位址分散情況下的 overhead),以下為連續的資料位址的合併情況。
- 16 * 4 bytes -> 64 bytes
- 16 * 8 bytes -> 128 bytes
- 16 * 16 bytes -> 256 bytes