平行處理系統分類
指令與資料
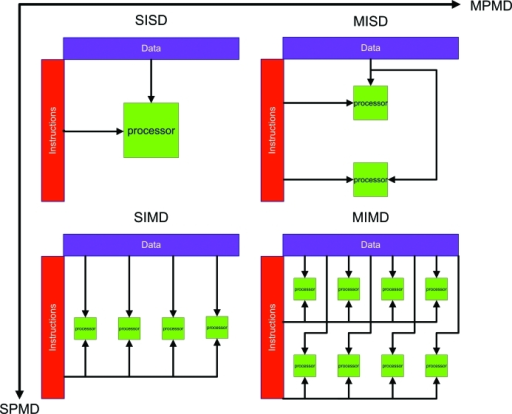
根據一個平行電腦能夠同時執行的指令與處理資料的多少可以把平行電腦分為Single-Instruction Multiple-Data (SIMD) 電腦和Multiple-Instruction Multiple-Data (MIMD )多指令多資料平行電腦。人們按同時執行的程式和資料的不同又提出了Single-Program Multuple-Data (SPMD) 單程式多資料平行電腦和 Multiple-Program Multiple-Data (MPMD)多程式多資料平行電腦。
SIMD電腦同時用相同的指令對不同的資料進行操作。比如對於陣列賦值運算 ,在SIMD並行機上可以用加法指令同時對陣列 的所有元素實現加1,即陣列或向量運算特別適合在SIMD平行電腦上執行SIMD並行機可以對這種運算形式進行直接地支持高效地實現。
MIMD電腦同時有多條指令對不同的資料進行操作比如對於算術運算式 ,可以轉換為 、加法、減法、以及乘法 ,如果有相應的直接執行部件則這三個不同的計算可以同時進行。
一般地SPMD平行電腦是由多個地位相同的電腦或處理器組成的。
而MPMD平行電腦內電腦或處理器的地位是不同的,根據分工的不同它們擅長完成的工作也不同。因此可以根據需要將不同的程序任務放到MPMD平行電腦上執行,使得這些程式協調一致地完成給定的工作。
依存儲方式分類
- 平行電腦的架構可概分為兩大類:
- 共用記憶體平行電腦(Shared Memory Parallel System, SMP)。
- 分散記憶體平行電腦(Distributed Memory Parallel System)。
SMP是往日超級電腦的縮小版,是多個同型 CPU 共用一個記憶體,每個 CPU 和共用記憶體之間或用Crossbar連結或用System-bus連結。現階段 SMP電腦系統的 CPU 個數以兩個、四個、八個最普遍,也有多到 16 個、或32 個 CPU 的機種,這些 CPU 是在一個作業系統之下運作的。Crossbar 的通道越多,可以連結的 CPU 個數亦越多,但是成本亦越高。System-bus 的資料傳輸頻寬是固定的,每一個 CPU 到共用記憶體的資料傳輸頻寬也是固定的,兩者的商就是可以連結 CPU 數目的上限。當然可以採用更大頻寬的 system-bus,其考慮的因素之一是工程技術是否做得到,另外一個因素是製造成本是否太高而會影響到產品銷路和獲利能力。
- SMP系統的特性:
- 所有處理器共享相同的記憶體空間。
- 當記憶體內容改變時,所有的處理器都知道此更新。
- 依記憶體的存取時間,可分為UMA與NUMA兩種架構。
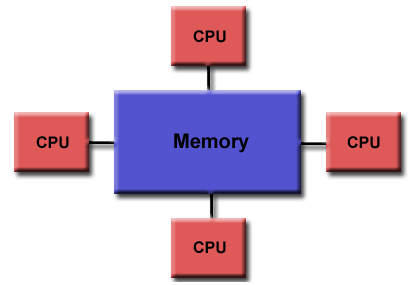
Uniform shared memory (UMA)
- 系統中使用相同的處理器。
- 對記憶體有相同的存取權與存取時間。
- 有時也稱為Cache coherent UMA (CC-UMA),外取一致性(Cache coherent)指當其中一個處理器更新記憶體內容時,所有其它的記憶體都會知道此更新。而此更新在是硬體層級完成的。
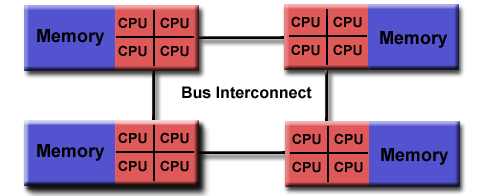
Non-uniform shared memory (NUMA)
- 通常連結了兩個或以上的SMP系統。
- 其中一組SMP可存取其它SMP系統的記憶體。
- 並非所有的處理器在存取記憶體時有相同的存取時間。
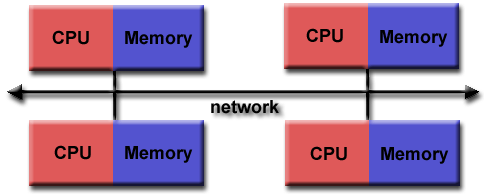
分散記憶體平行電腦系統是多個獨立電腦的集合體,每一個獨立的電腦有它自己的 CPU、記憶體、和操作系統。目前在高速計算上常用的分散記憶體平行電腦系統是工作站群(Workstation Clusters),最簡陋的工作站群是透過乙太網路(Ethernet)或 FDDI 網路把若干個分散的工作站連結在一起。但是低速的乙太網路的傳輸速度太慢,平行計算的成效會打折扣。常見的工作站群是把若干個(兩個、四個、八個、或十六個)獨立的高階工作站處理器連同硬碟機等其他配備裝在一個箱架上,各個處理器之間利用特製的高速網路連結在一起,箱架和箱架之間也是利用特製的高速網路來連結。高速網路的連結方式有階層式(Hierarchy)、環狀(Ring)、十字交叉網(Crossbar)等多種,各廠商選用自認為最有效的連結方式。這種電腦系統可以連結的 CPU 個數相當多,可以到達 512 個、1024 個或更多,所以又叫做大量平行電腦系統(Massive Parallel Processors),簡稱 MPP。
平行電腦的運作管理
使用者的角度來看 SMP 電腦系統,不管它有幾個 CPU,在感覺上它像只有一個 CPU 一樣。當你進入該電腦系統之後,可以進行程式的修改、編譯和執行。但是這些工作是在那一個 CPU 上執行的呢?你不知道,你不用知道,你也不用管。該 SMP 的操作系統會把這些工作交給負載較輕的 CPU 去執行,你是跟一個操作系統打交道,你也不能指定要用那一個 CPU。所以 SMP 電腦系統本身就可以做到各個 CPU 之間負載的均衡分佈(Load Balancing)。
MPP 就不一樣,在設定的範圍之內,你可以進入你想要的那一個 CPU,在該 CPU 上進行程式的修改、編譯和執行。因此,在多人使用的環境之下,各個 CPU 負載的輕重可能相差非常懸殊。造成有些 CPU 負載很重,另外一些 CPU 卻沒有事做而形成資源的浪費。因此就必須借助於像 NQS (Network Queue System)等排程軟體系統來做系統的自動管理工作。你把待執行的工作程序寫在一個工作命令檔(Job Command File)上,然後把它交給排程軟體系統。該排程軟體系統就會把你的工作交給負載最輕的 CPU 來執行,以達到負載的均衡分佈與資源的充分利用,等到你的工作執行完畢之後,排程軟體會把執行的結果抄回來給你。
一般的排程軟體系統還備有其他功能,像可以根據工作需時長短、需要記憶容量的多寡等特性將工作分類。每一個工作類別指定在那幾個 CPU 上來執行,每一個工作類別也可以規定執行工作數量的上限,超過設定上限的工作就必須排隊等候處理,以免擠進去太多的工作而影響到電腦執行的效率,也使得各種不同資源需求的工作都能夠獲得接近平等的服務。使用人可以根據自己工作的特性選擇其中一類來執行。排程軟體系統也可以規定每一個用戶同時可以丟幾個工作進去,超過設定上限的工作就會被退回來,以保障每一個用戶均等使用電腦資源的機會。所以排程軟體系統也適用於 SMP 電腦系統。
在 SMP 電腦系統上的每一個 CPU 都是共用一個記憶體,所以你的程式所用到的資料都是放在同一個區域裡,每一個 CPU 都是到該區域裡去存取資料,沒有 CPU 之間 的資料傳輸問題。這種平行化通常是在 loop 上進行,所以是屬於細顆粒平行(Fine Grained Parallel),當然並不是每一個 loop 都可以平行化。能力比較強的編譯器可以做到副程式間的資料分析,也可以把含有叫用副程式的 loop 加以平行化,做到粗顆粒平行(Coarse Grained Parallel) 。
目前,在 MPP 上做平行計算比較複雜,你必須把程式用到的資料和計算工作做適當的切割,把不同的資料區塊分別傳送到各個 CPU 的記憶體裡,然後各個 CPU 各自計算放在該 CPU 記憶體裡的資料。如果要用到其他 CPU 記憶體裡所存放的資料時,就要經由 CPU 間的網路從該CPU 取得該項資料後,才能夠繼續計算下去。 現階段 MPP 各個 CPU 之間 高速網路的資料傳輸速度比 CPU 到自己記憶體內的資料傳輸速度要慢很多倍,因此 CPU 之間傳送的資料越少,平行計算的效率就越高。在 MPP 電腦系統上做平行計算必須使用「訊息傳送(Message passing)」語言來撰寫,常用的訊息傳送語言有 PVM (Parallel Virtual Machine)和 MPI (Message Passing Interface)等多種。
如果你有一個循序程式(Sequential Code)要在 MPP 上平行化,你必須先學會一種訊息傳送語言,然後再把你的程式和該程式用到的資料做適當的切割、重組(Restructrue),然後加入訊息傳送副程式改寫你的程式,經過編譯之後才能執行。除了少數例外,一般在單一 CPU 系統上開發出來的循序程式要在 MPP 電腦系統上平行化,要費相當大的心力,有時候還必須換用合適的演算法(Algorithm),才容易平行化。
在把一個循序程式平行化之前,選擇一個有效率而且資料容易切割的演算法,恐怕是最重要的工作。一個需要冗長計算時間的程式如果能換用一個更有效率的演算法,也許在短時間裡就可以得到計算結果,單一 CPU 就已足夠,根本不必花費那麼多心力去做平行化工作。如果還是有需要借用平行計算來縮短跑程時間(Turn-around Time),一個容易切割的演算法,可以節省很多程式設計心力,在較短的時間裡完成平行化工作,而且達到較高的平行效率。