Postgresql SQL筆記
- PostgreSQL 的每個資料表中都包含幾個隱含定義的系統欄位。因此,這些名字不能用於用戶定義的欄位名。這些系統欄位的功能有些類似於 Oracle 中的 rownum 和 rowid 等。
- oid: 行的物件識別碼(對象 ID)。這個欄位只有在創建表的時候使用了 WITH OIDS,或者是設置了配置參數default_with_oids 時出現。這個欄位的類型是 oid(和欄位同名)。
- tableoid: 包含本行的表的 OID。這個欄位對那些從繼承層次中選取的查詢特別有用,因為如果沒有它的話,我們就很難說明一行來自哪個獨立的表。tableoid 可以和 pg_class 的 oid 欄位連接起來獲取表名字。
- xmin: 插入該行版本的事務的標識(事務 ID)。
- cmin: 在插入事務內部的命令標識(從零開始)。
- xmax: 刪除事務的標識(事務 ID),如果不是被刪除的行版本,那麼是零。
- cmax: 在刪除事務內部的命令識別字,或者是零。
- ctid: 一個行版本在它所處的表內的物理位置。請注意,儘管 ctid 可以用於非常快速地定位行版本,但每次 VACUUM FULL 之後,一個行的 ctid 都會被更新或者移動。因此 ctid 是不能作為長期的行識別字的。OID 是 32 位的量,是在同一個集群內通用的計數器上賦值的。對於一個大型或者長時間使用的資料庫,這個計數器是有可能重疊的。因此,假設 OID 是唯一的是非常錯誤的,除非你自己採取了措施來保證它們是唯一的。如果你需要標識表中的行,我們強烈建議使用序號生成器。
SELECT
SELECT "col_name1", "col_name2",... FROM "table_name";
DISTINCT
- SELECT 指令讓我們能夠讀取表格中一個或數個欄位的所有資料。 這將把所有的資料都抓出,無論資料值有無重複。在資料處理中,我們會經常碰到需要找出表格內的不同 資料值的情況。換句話說,我們需要知道這個表格/欄位內有哪些不同的值,而每個值出現的次數並不重要。 這要如何達成呢?在 SQL 中, 這是很容易做到的。我們只要在 SELECT 後加上一個 DISTINCT 就可以了。
E.g. table Store_Information={store_name, sales, txn_date};
-- 找出不同的店名 SELECT DISTINCT Store_Name FROM Store_Information;WHERE
需要選擇性地抓資料需要用到 WHERE 這個指令。
E.g. table Store_Information={store_name, sales, txn_date};
SELECT Store_Name FROM Store_Information WHERE Sales > 1000;
- 多個條件時可用and/or
SELECT "欄位名" FROM "表格名" WHERE "簡單條件" {[AND|OR] "簡單條件"}+;
SELECT Store_Name FROM Store_Information WHERE Sales > 1000 OR (Sales < 500 AND Sales > 275);
新增、移除資料表
建立資料表
CREATE TABLE products (
--SERIAL类型的字段表示该字段为自增字段,完全等同Oracle中的Sequence。
product_no SERIAL,
name text,
--DEFAULT是關鍵字,其後的數值9.99是欄位price的預設值。
price numeric DEFAULT 9.99
);
刪除資料表
DROP TABLE products;
新增欄位
- 新增的欄位對於表中已經存在的行而言最初將先填充所給出的缺省值(如果你沒有聲明 DEFAULT 子句,那麼缺省是空值)。
- 在新增欄位時,可以同時給該欄位指定約束。
ALTER TABLE products ADD COLUMN description text;
-- with constraint
ALTER TABLE products ADD COLUMN description text CHECK(description <> '');
刪除欄位
- 如果該表為被引用表,該欄位為被引用欄位(外鍵約束),那麼上面的刪除操作將會失敗。
ALTER TABLE products DROP COLUMN description;
- 如果要想在刪除被引用欄位的同時級聯的刪除其所有引用欄位,可以採用下面的語法形式。
ALTER TABLE products DROP COLUMN description CASCADE;
增加約束
-- 增加一個表級約束
ALTER TABLE products ADD CHECK(name <> '');
--增加命名的唯一性約束。
ALTER TABLE products ADD CONSTRAINT some_name UNIQUE(product_no);
--增加外鍵約束。
ALTER TABLE products ADD FOREIGN KEY(pdt_grp_id) REFERENCES pdt_grps;
--增加一個非空約束。
ALTER TABLE products ALTER COLUMN product_no SET NOT NULL;
刪除約束
ALTER TABLE products DROP CONSTRAINT some_name;
對於顯示命名的約束,可以根據其名稱直接刪除,對於隱式自動命名的約束,可以通過 psql 的\d tablename 來獲取該約束的名字。和刪除欄位一樣,如果你想刪除有著被依賴關係地約束,你需要用 CASCADE。一個例子是某個外鍵約束依賴被引用欄位上的唯一約束或者主鍵約束。
和其他約束不同的是,非空約束沒有名字,因此只能通過下面的方式刪除:
ALTER TABLE products ALTER COLUMN product_no DROP NOT NULL;
改變欄位的缺省值
- 在為已有欄位添加缺省值時,不會影響任何表中現有的資料行, 它只是為將來 INSERT 命令改變缺省值。
ALTER TABLE products ALTER COLUMN price SET DEFAULT 7.77;
-- 刪除預設值
ALTER TABLE products ALTER COLUMN price DROP DEFAULT
修改欄位的資料類型
- 只有在欄位裡現有的每個項都可以用一個隱含的類型轉換轉換成新的類型時才可能成功。
- 比如當前的資料都是整型,而轉換的目標類型為 numeric 或 varchar,這樣的轉換一般都可以成功。
- 與此同時,PostgreSQL 還將試圖把欄位的缺省值(如果存在)轉換成新的類型,還有涉及該欄位的任何約束。
- 但是這些轉換可能失敗,或者可能生成奇怪的結果。在修改某欄位類型之前,你最好刪除那些約束,然後再把自己手工修改過的添加上去。
ALTER TABLE products ALTER COLUMN price TYPE numeric(10,2);
修改欄位名
ALTER TABLE products RENAME COLUMN product_no TO product_number;
修改表名
ALTER TABLE products RENAME COLUMN product_no TO product_number;
約束(Constraint)
使用隱式命名的型態約束
CREATE TABLE products (
product_no integer,
name text,
--price欄位的值必須大於0,否則在插入或修改該欄位值是,將引發違規錯誤。還需要說明的是,該檢查約束
--是匿名約束,即在表定義時沒有顯示命名該約束,這樣PostgreSQL將會根據當前的表名、欄位名和約束類型,
--為該約束自動命名,如:products_price_check。
price numeric CHECK (price > 0)
);
使用顯示命名的型態約束
CREATE TABLE products (
product_no integer,
name text,
--該欄位的檢查約束被顯示命名為positive_price。
--這樣做好處在於今後維護該約束時,可以根據該名進行直接操作。
price numeric CONSTRAINT positive_price CHECK (price > 0)
);
非空約束
CREATE TABLE products (
product_no integer NOT NULL,
name text NOT NULL,
price numeric
);
唯一性約束
+ 在插入資料時,空值(NULL)之間被視為不相等的資料,因此對於某一唯一性欄位,可以多次插入空值。然而需要注
意的是,這一規則並不是被所有資料庫都遵守,因此在進行資料庫移植時可能會造成一定的麻煩。
CREATE TABLE products (
product_no integer UNIQUE,
name text,
price numeric
);
-- or
CREATE TABLE products (
product_no integer,
name text,
price numeric,
UNIQUE (product_no)
);
-- 命名
CREATE TABLE products (
product_no integer CONSTRAINT must_be_different UNIQUE,
name text,
price numeric
);
多欄位聯合唯一性約束
CREATE TABLE example (
a integer,
b integer,
c integer,
UNIQUE (a, c)
);
主鍵與外鍵(key and foreign key)
單一主鍵
+ 技術上來說,主鍵約束只是唯一約束和非空約束的組合。
CREATE TABLE products (
-- 字段product_no被定义为该表的唯一主键。
product_no integer PRIMARY KEY,
name text,
price numeric
);
聯合主鍵
CREATE TABLE example (
a integer,
b integer,
c integer,
PRIMARY KEY (b, c)
);
外鍵約束
- 聲明一個欄位(或者一組欄位)的數值必須匹配另外一個表中某些行出現的數值。
- 我們把這個行為稱做兩個相關表之間的參考完整性。
CREATE TABLE orders (
-- 該表的product_no欄位為上面products表主鍵(product_no)的外鍵。
order_id integer PRIMARY KEY,
product_no integer REFERENCES products(product_no),
quantity integer
);
CREATE TABLE t1 (
a integer PRIMARY KEY,
b integer,
c integer,
-- 該外鍵的欄位數量和被引用表中主鍵的數量必須保持一致。
FOREIGN KEY (b, c) REFERENCES example (b, c)
);
當多個表之間存在了主外鍵的參考性約束關係時,如果想刪除被應用表(主鍵表)中的某行記錄,由於該行記錄的主 鍵欄位值可能正在被其引用表(外鍵表)中某條記錄所關聯,所以刪除操作將會失敗。如果想完成此操作,一個顯而易見 的方法是先刪除引用表中和該記錄關聯的行,之後再刪除被引用表中的該行記錄。
Postgresql提供了更為方便的方式完成此類操作。
- RESTRICT: 禁止刪除被引用的行。
- NO ACTION 的意思是如果在檢查約束的時候,如果還存在任何引用行,則拋出錯誤;如果你不聲明任何東西,那麼它就是缺省的行為。(這兩個選擇的實際區別是,NO ACTION 允許約束檢查推遲到事務的晚些時候,而 RESTRICT 不行。)
- CASCADE 聲明在刪除一個被引用的行的時候,引用它的行也會被自動刪除掉。
- 在外鍵欄位上的動作還有兩個選項: SET NULL 和 SET DEFAULT。
- 這樣會導致在被引用行刪除的時候,引用它們的欄位分別設置為空或者缺省值。
- 請注意這些選項並不能讓你逃脫被觀察和約束的境地。比如,如果一個動作聲明 SET DEFAULT,但是缺省值並不能滿足外鍵,那麼動作就會失敗。
- 類似ON DELETE,還有 ON UPDATE 選項,它是在被引用欄位修改(更新)的時候調用的。可用的動作是一樣的。
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
CREATE TABLE orders (
order_id integer PRIMARY KEY,
shipping_address text
);
CREATE TABLE order_items (
product_no integer REFERENCES products ON DELETE RESTRICT, --限制選項
order_id integer REFERENCES orders ON DELETE CASCADE, --級聯限制選項
quantity integer,
PRIMARY KEY (product_no, order_id)
);
權限管理
- 只有表的所有者才能修改或者刪除表的許可權。
- 要賦予一個許可權,我們使用 GRANT 命令。
- 要撤銷一個許可權,使用REVOKE 命令。
- 需要指出的是,PUBLIC 是特殊"用戶"可以用於將許可權賦予系統中的每一個使用者。在聲明許可權的位置寫 ALL 則將所有的與該物件類型相關的許可權都賦予出去。
- 最初,只有物件擁有者(或者超級用戶)可以賦予或者撤銷物件的許可權。但是,我們可以賦予一個"with grant option"許可權,這樣就給接受許可權的人以授予該許可權給其它人的許可權。如果授予選項後來被撤銷,那麼所有那些從這個接受者接受了許可權的用戶(直接或者通過級連的授權)都將失去該許可權。
--將表的更新許可權賦予指定的user
GRANT UPDATE ON table_name TO user;
--將表的select許可權賦予指定的組。
GRANT SELECT ON table_name TO GROUP group;
--將表的所有權限從Public撤銷。
REVOKE ALL ON table_name FROM PUBLIC;
模式(schema)
一個資料庫包含一個或多個命名的模式,模式又包含表。模式還包含其它命名的物件,包括資料類型、函數,以及操作符。同一個物件名可以在不同的模式裡使用而不會導致衝突;
- 比如,schema1 和 myschema 都可以包含叫做 mytable的表。
- 和資料庫不同,模式不是嚴格分離的:一個使用者可以訪問他所連接的資料庫中的任意模式中的物件,只要他有權限。
- 以行為來看,schema類似python當中的package。
使用模式有以下幾個主要原因:
- 允許多個使用者使用一個資料庫而不會干擾其它使用者。
- 把資料庫物件組織成邏輯組,讓它們更便於管理。
- 協力廠商的應用可以放在不同的模式中,這樣它們就不會和其它物件的名字衝突。
建立schema
- 通過命令可以創建名字為 myschema 的模式,在該模式被創建後,其便可擁有自己的一組邏輯物件,如表、視圖和函數等。
CREATE SCHEMA myschema;
public模式
- 每當我們創建一個新的資料庫時,PostgreSQL 都會為我們自動創建該模式。當登錄到該資料庫時,如果沒有特殊的指定,我們將以該模式(public)的形式操作各種資料對象。
CREATE TABLE products ( ... ) 等同於 CREATE TABLE public.products ( ... )
schema權限
- 缺省時,使用者看不到模式中不屬於他們所有的對象。為了讓他們看得見,模式的所有者需要在模式上賦予 USAGE許可權。
- 為了讓使用者使用模式中的物件,我們可能需要賦予額外的許可權,只要是適合該物件的。
- PostgreSQL 根據不同的物件提供了不同的許可權類型
GRANT ALL ON SCHEMA myschema TO public;
- 上面的 ALL 關鍵字將包含 CREATE 和 USAGE 兩種許可權。如果 public 模式擁有了 myschema 模式的 CREATE許可權,那麼登錄到該模式的使用者將可以在 myschema 模式中創建任意物件。
CREATE TABLE myschema.products (
product_no integer,
name text,
price numeric CHECK (price > 0),
);
- 在為模式下的所有表賦予許可權時,需要將許可權拆分為各種不同的表操作。
ALTER DEFAULT PRIVILEGES IN SCHEMA myschema GRANT INSERT, SELECT, UPDATE, DELETE, TRUNCATE, REFERENCES, TRIGGER ON TABLESTO public;
- 在為模式下的所有 Sequence 序列物件賦予許可權時,需要將許可權拆分為各種不同的 Sequence 操作,如:
ALTER DEFAULT PRIVILEGES IN SCHEMA myschema GRANT SELECT, UPDATE, USAGE ON SEQUENCES TO public;
- 在為模式下的所有函數賦予許可權時,僅考慮執行許可權,如:
ALTER DEFAULT PRIVILEGES IN SCHEMA myschema GRANT EXECUTE ON FUNCTIONS TO public;
- 可以看出,通過以上方式在 public 模式下為 myschema 模式創建各種物件是極為不方便的。
- 我們將要介紹另外一種方式,即通過 role 物件,直接登錄並關聯到 myschema 物件,之後便可以在 myschema 模式下直接創建各種所需的對象了。
-- 創建了和該模式關聯的角色物件。
CREATE ROLE myschema LOGIN PASSWORD '123456';
-- 將該模式關聯到指定的角色,模式名和角色名可以不相等。
CREATE SCHEMA myschema AUTHORIZATION myschema;
- 在 Linux Shell 下,以 myschema 的角色登錄到資料庫 MyTest,在密碼輸入正確後將成功登錄到該資料庫。
psql -d MyTest -U myschema
刪除schema
DROP SCHEMA myschema;
DROP SCHEMA myschema CASCADE;
schema搜尋路徑
我們在使用一個資料庫物件時可以使用它的全稱來定位物件,然而這樣做往往也是非常繁瑣的,每次都不得不鍵入owner_name.object_name。
- PostgreSQL 中提供了模式搜索路徑,這有些類似於 Linux 中的$PATH 環境變數,當我們執行一個 Shell 命令時,只有該命令位於$PATH 的目錄清單中,我們才可以通過命令名直接執行,否則就需要輸入它的全路徑名。
- PostgreSQL 同樣也通過查找一個搜索路徑來判斷一個表究竟是哪個表,這個路徑是一個需要查找的模式清單。在搜索路徑裡找到的第一個表將被當作選定的表。如果在搜索路徑中 沒有匹配表,那麼就報告一個錯誤。即使匹配表的名字在資料庫其它的模式中存在也如此。
在搜索路徑中的第一個模式叫做當前模式。除了是搜索的第一個模式之外,它還是在 CREATE TABLE 沒有聲明模式名的時候,新建表所屬於的模式。要顯示當前搜索路徑,使用 SHOW search_path;
search_path
----------------
"$user",public
(1 row)
可以將新模式加入到搜索路徑中,如: SET search_path TO myschema,public;
為搜索路徑設置指定的模式:
SET search_path TO myschema;
-- 當前搜索路徑中將只包含myschema一種模式。
資料表的繼承
- capitals 表繼承自 cities 表的所有屬性。在 PostgreSQL 裡,一個表可以從零個或多個其它表中繼承屬性,而且一個查詢既可以引用父表中的所有行,也可以引用父表的所有行加上其所有子表的行,其中後者是缺省行為。
CREATE TABLE cities ( --父表
name text,
population float,
altitude int
);
CREATE TABLE capitals ( --子表
state char(2)
) INHERITS (cities);
INSERT INTO cities values('Las Vegas', 1.53, 2174); --插入父表
INSERT INTO cities values('Mariposa',3.30,1953); -- 插入父表
INSERT INTO capitals values('Madison',4.34,845,'WI'); --插入子表
--父表和子表的数据均被取出
SELECT name, altitude FROM cities WHERE altitude > 500;
name | altitude
-----------+----------
Las Vegas | 2174
Mariposa | 1953
Madison | 845
(3 rows)
--只有子表的数据被取出。
SELECT name, altitude FROM capitals WHERE altitude > 500;
name | altitude
---------+----------
Madison | 845
(1 row)
- 如果希望只從父表中提取資料,則需要在 SQL 中加入 ONLY 關鍵字
- "ONLY"關鍵字表示該查詢應該只對 cities 進行查找而不包括繼承級別低於 cities 的表。
- 許多我們已經討論過的命令--SELECT,UPDATE 和 DELETE--支援這個"ONLY"符號。
SELECT name,altitude FROM ONLY cities WHERE altitude > 500;
name | altitude
-----------+----------
Las Vegas | 2174
Mariposa | 1953
(2 rows)
- 在執行整表資料刪除時,如果直接 truncate 父表,此時父表和其所有子表的資料均被刪除,如果只是 truncate 子表,那麼其父表的資料將不會變化,只是子表中的資料被清空。
TRUNCATE TABLE cities; -- 父表和子表的数据均被删除。
確定資料來源
- 有時候你可能想知道某條記錄來自哪個表。在每個表裡我們都有一個系統隱含欄位 tableoid,它可以告訴你表的來源
SELECT tableoid, name, altitude FROM cities WHERE altitude > 500;
tableoid | name | altitude
----------+-----------+----------
16532 | Las Vegas | 2174
16532 | Mariposa | 1953
16538 | Madison | 845
(3 rows)
- 以上的結果只是給出了 tableoid,僅僅通過該值,我們還是無法看出實際的表名。要完成此操作,我們就需要和系統表 pg_class 進行關聯,以通過 tableoid 欄位從該表中提取實際的表名,見以下查詢:
SELECT p.relname, c.name, c.altitude FROM cities c,pg_class p WHERE c.altitude > 500
and c.tableoid = p.oid;
relname | name | altitude
----------+-----------+----------
cities | Las Vegas | 2174
cities | Mariposa | 1953
capitals | Madison | 845
(3 rows)
資料插入的注意事項
- 繼承並不自動從 INSERT 或者 COPY 中向繼承級別中的其它表填充資料。在我們的例子裡,下面的 INSERT 語句不會成功:
- 我們可能希望資料被傳遞到 capitals 表裡面去,但是這是不會發生的:INSERT 總是插入明確聲明的那個表。
-- failed
INSERT INTO cities (name, population, altitude, state) VALUES ('New York', NULL, NULL, 'NY');
多重繼承
*一個表可以從多個父表繼承,這種情況下它擁有父表們的欄位的總和。子表中任意定義的欄位也會加入其中。
+ 如果同一個欄位名出現在多個父表中,或者同時出現在父表和子表的定義裡,那麼這些欄位就會被"融合",這樣在子表裡面
就只有一個這樣的欄位。
+ 要想融合,欄位必須是相同的資料類型,否則就會拋出一個錯誤。融合的欄位將會擁有它所繼承的欄位的所有約束。
CREATE TABLE parent1 (FirstCol integer);
CREATE TABLE parent2 (FirstCol integer, SecondCol varchar(20));
CREATE TABLE parent3 (FirstCol varchar(200));
-- 子表child1將同時繼承自parent1和parent2表,
-- 而這兩個父表中均包含integer類型的FirstCol欄位,
-- 因此child1可以創建成功。
CREATE TABLE child1 (MyCol timestamp) INHERITS (parent1,parent2);
-- 子表child2將不會創建成功,因為其兩個父表中均包含FirstCol欄位,
-- 但是它們的類型不相同。
CREATE TABLE child2 (MyCol timestamp) INHERITS (parent1,parent3);
-- 子表child3同樣不會創建成功,因為它和其父表均包含FirstCol欄位,
-- 但是它們的類型不相同。
CREATE TABLE child3 (FirstCol varchar(20)) INHERITS(parent1);
繼承與權限
表存取權限並不會自動繼承。因此,一個試圖訪問父表的用戶還必須具有訪問它的所有子表的許可權,或者使用 ONLY 關鍵字只從父表中提取資料。在向現有的繼承層次添加新的子表的時候,請注意給它賦予所有權限。
繼承特性的一個嚴重的局限性是索引(包括唯一約束)和外鍵約束只施用於單個表,而不包括它們的繼承的子表。這一點不管對引用表還是被引用表都是事實,因此在上面的例子裡,如果我們聲明 cities.name 為 UNIQUE 或者是一個PRIMARY KEY,那麼也不會阻止 capitals 表擁有重複了名字的 cities 資料行。 並且這些重複的行缺省時在查詢 cities表的時候會顯示出來。實際上,缺省時 capitals 將完全沒有唯一約束,因此可能包含帶有同名的多個行。你應該給capitals 增加唯一約束,但是這樣做也不會避免與 cities 的重複。類似,如果我們聲明 cities.name REFERENCES 某 些其它的表,這個約束不會自動廣播到 capitals。在這種條件下,你可以通過手工給 capitals 增加同樣的 REFERENCES 約束來做到這點。
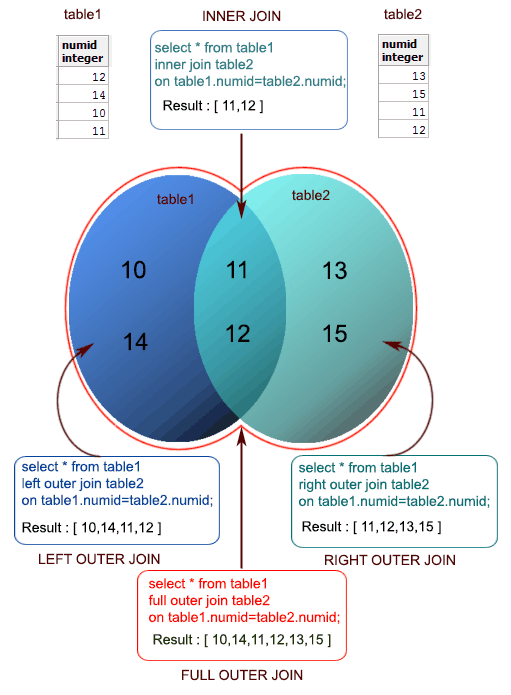
Join
T1 { [INNER] | { LEFT | RIGHT | FULL } [OUTER] } JOIN T2 ON boolean_expression
T1 { [INNER] | { LEFT | RIGHT | FULL } [OUTER] } JOIN T2 USING ( join column list )
T1 NATURAL { [INNER] | { LEFT | RIGHT | FULL } [OUTER] } JOIN T2
trigger
觸發(Triggers)是當 Table 或是 View 因為 Insert、Delete、Update動作發生時自動觸發的程序(或是因為特定事件的發生,例如:服務啟動)。可以用來描述商業邏輯。跟 stored procedure 很類似,差別在於它不是用來直接呼叫的。
通常 trigger 被用來作為以下幾項用途:
- 資料完整性的檢查
- 稽核與日誌紀錄功能
- 執行複雜的商業邏輯運算與處理
- 衍生欄位資料的計算與產生
- 讓 table 資料有限制的被修改
整個 trigger 可以分為四個部份:
- trigger name: 在同一個 schema 中,trigger name 必須是唯一的。
- triggering statement : 指定讓 trigger 啟動的事件,這些事情可能包含 DML(for table)、DDL(for schema object) 或是資料庫服務啟動、關閉、甚至是發生錯誤時。
- trigger restriction: 額外設定的限制,可讓 trigger 在特定情況下(當 restriction = TRUE 時)才啟動。
- triggered action: trigger 所要執行的程式內容。
Trigger 的設計原則與限制
- 雖然 trigger 看似很好用,可以作很多的管理與控制,但最好還是注意以下幾點原則與限制:
- 過度使用 trigger 或許會產生複雜的依賴關係,後續的維護變得很困難。
- 確定當某個特定工作執行後,所有相關與相依的工作都有被一一執行。
- 避免將 recursive trigger 的發生,否則記憶體裝再多都沒用。
- 避免 trigger 的工作會觸發另一個 trigger 而造成連鎖效應,以免造成非預期的情況發生,或是對資料庫效能造成影響。
- 不要用 trigger 作一些資料庫已經能做的工作,例如:參考完整性的檢查。
- 確定「BEFORE」、「AFTER」的使用有符合規則與需求。
- trigger 的程式碼不宜過多(Oracle 限制不能超過 32 Kb),若是程式碼太多,或許可以考慮寫成 stored procedure 來處理。
- 確定 trigger 中運作的工作符合資料庫與商業邏輯規則,若是要針對特定人物、特定團體或是特定 application 客製化工作需求,別用 trigger,寫在 application 裡面吧!
- 在 trigger 中無法使用 COMMIT、ROLLBACK、SAVEPOINT … 等關鍵字,因為 DDL 操作已經隱含 COMMIT 在裡面了。
觸發(Trigger)的種類
在 Oracle 中,trigger 大致可分為五類:
statement trigger:
- 此種 trigger 跟 DML 操作(例如:DELETE、INSERT、UPDATE)有關聯,但每一次的 DML 操作僅會觸發一次 trigger。
- 雖然設定在 DML 操作上的 trigger 在 DML 操作發生時僅會出發一次,但可以同時設定多個 trigger 在同一個 DML 操作上,而且還可以透過「FOLLOW」、「PRECEDES」… 等關鍵字來決定多個 trigger 觸發的先後順序。
row trigger
- 當 table 中的每一列資料發生 INSERT、UPDATE 或是 DELETE 時,此種 trigger 就會觸發。大致跟 statement trigger 運作方式相同,但 row trigger 是針對「每一列」資料進行觸發;因此假設一個 DML 同時影響很多筆資料時,statement trigger 僅會出發一次,但 row trigger 卻會觸發很多次。
INSTEAD OF + 可以用在當使用者針對 VIEW 或是衍生欄位進行操作時,可透過 trigger 將資料進行正確的資料處理。
user event trigger
- 用於 DDL(例如:CREATE、ALTER、DROP、USER LOGON/LOGOFF … 等等) 以及特定的 DML 操作(分析、統計、稽核、使用者權限管理)上。
system event trigger
- 當資料庫啟動、關閉、或是發生錯誤的事件發生時,會進行觸發。
Trigger 發生的時間點
trigger 發生的時間點也必須要注意,因為在 trigger statement 中,有「BEFORE」與「AFTER」兩種可供使用,表示 trigger 觸發的時間點位於「事件發生前」或是「事件發生後」。
但也不是每個事件都有前後可以設定,例如:STARTUP、SUSPEND、LOGON … 等事件,就僅有 AFTER 可以用;而 SHUTDOWN、LOGOFF … 等事件就僅有 BEFORE 可以用。